Claude Code competitive intelligence works when you enforce three architectural rules: separate evidence collection from interpretation, prioritize CRM data over web search, and tag every claim with a confidence tier. I built this system after a contaminated battlecard poisoned 6 weeks of sales conversations, and the architecture now produces competitive briefs that sales actually trusts because every claim traces back to a source.
The Problem With Most AI Competitive Intelligence
Here's what happens in the typical AI competitive analysis workflow: someone opens ChatGPT, pastes "analyze competitor X vs our product," and gets a plausible-sounding comparison. The comparison includes real product names, real feature categories, and a confident tone. Maybe 60% of the claims are accurate. The other 40% range from outdated to fabricated.
The sales team uses it anyway because it looks professional and nobody has time to verify every line. Three weeks later, a prospect says "that's not really what they do" during a call. By then, the framing has already shaped how your team thinks about the competitive landscape.
I've watched this pattern play out at three different companies. The failure mode isn't that AI produces bad competitive intelligence. It's that AI produces confident-sounding competitive intelligence with no mechanism to distinguish verified facts from plausible guesses. The format hides the uncertainty.
The architectural fix isn't a better prompt. It's a system that separates what's known from what's inferred, and that starts with the data closest to your actual deals.
The CRM-First Principle
Most competitive intelligence workflows start with web search. Company websites, G2 reviews, news articles, social media. These are useful sources. They're also the wrong starting point.
Your CRM contains competitive intelligence that no web search can match:
- Which competitors show up in your actual deals. Not which competitors exist in the market. Which ones your prospects are evaluating right now.
- Win/loss reasons against specific competitors. Not analyst frameworks. Actual notes from reps who won or lost deals against Competitor X.
- Pricing intelligence from real negotiations. Not published pricing pages. What prospects told your team about competitive quotes.
- Feature comparison gaps from deal objections. Not feature comparison matrices from review sites. Specific features that came up as objections in deals you lost.
At one consulting engagement, we pulled 14 months of CRM data before touching a single web source. The CRM showed that the client's top competitor by deal overlap wasn't the company they spent the most energy positioning against. They'd been building battlecards for Competitor A while Competitor B showed up in 3x more active deals. That insight was invisible from web research alone.
The CRM-first principle is simple: query your own deal data before querying the internet. Your CRM is priority-0. Web sources fill gaps that CRM data doesn't cover.
Implementing CRM-First in Claude Code
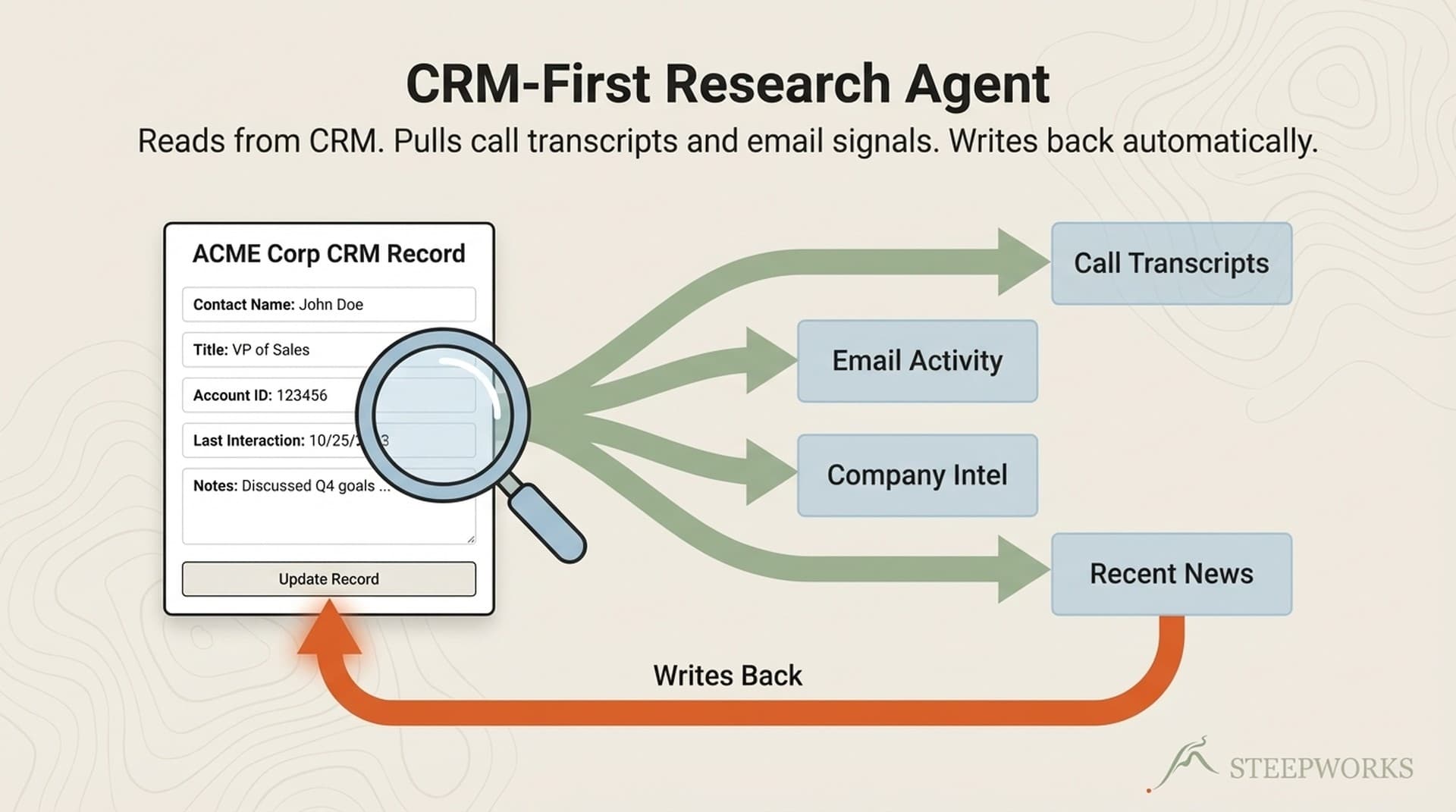
Claude Code connects to CRM tools through MCP (Model Context Protocol) integrations. If your HubSpot, Salesforce, or Monday.com instance has an API, Claude Code can query it directly.
The research-prospect skill follows this priority chain:
- CRM data. Deal history, contact interactions, competitive mentions, win/loss notes
- First-party data. Your own knowledge base, past research, internal wikis
- Second-party data. Review sites (G2, Gartner), industry reports you subscribe to
- Third-party data. Web search, news, social media, company websites
Each source gets a provenance tag: [CRM: HubSpot, as of 2026-04-20] or [WEB: G2 review, accessed 2026-04-25]. When a claim appears in the final output, the reader knows where it came from and how fresh it is.
The provenance tags changed how our sales team consumed competitive briefs. Before tagging, they treated every claim equally. After tagging, they naturally weighted CRM-sourced claims higher because they recognized the data. "We lost 3 deals to their enterprise tier in Q1" hits differently when it's tagged [CRM: HubSpot closed-lost analysis] versus sitting anonymously alongside web-sourced claims.
Upstream/Downstream Separation: The Core Architecture
I wrote about this principle in depth previously. Here's the compressed version and how it applies specifically to competitive intelligence.
Upstream agents collect evidence. They describe reality. They don't score, rank, or recommend.
Downstream agents interpret evidence. They score competitors, rank threats, recommend positioning, generate battlecards.
Never blend them. The moment you ask one agent to research a competitor AND tell you what to do about it, the interpretation contaminates the research. The agent develops a narrative while collecting facts, and the narrative shapes which facts it emphasizes.
We audited 43 research prompts across our system. Twenty-two of them blended upstream and downstream functions in a single pass. The contamination rate was 51%. Every contaminated prompt produced outputs where the "research" section already had a point of view.
Two Contamination Vectors
Vector 1: Role blending. One prompt does both research and strategy. "Research Competitor X and recommend positioning." The fix: split into two prompts. Prompt 1 collects evidence. Prompt 2, running separately on Prompt 1's output, interprets and recommends.
Vector 2: Tone bias. The research prompt uses loaded language. "Analyze Competitor X's aggressive pricing strategy" presupposes that the pricing is aggressive. The fix: neutral framing. "Document Competitor X's pricing structure, tier names, published prices, and any pricing changes in the last 12 months."
Both vectors are invisible in the output because the facts are usually accurate. The contamination is in the framing, emphasis, and narrative arc. A clean competitive brief reads like an intelligence report. A contaminated one reads like a persuasion document pretending to be research.
Building the Two-Agent Pipeline
In Claude Code, the separation is structural:
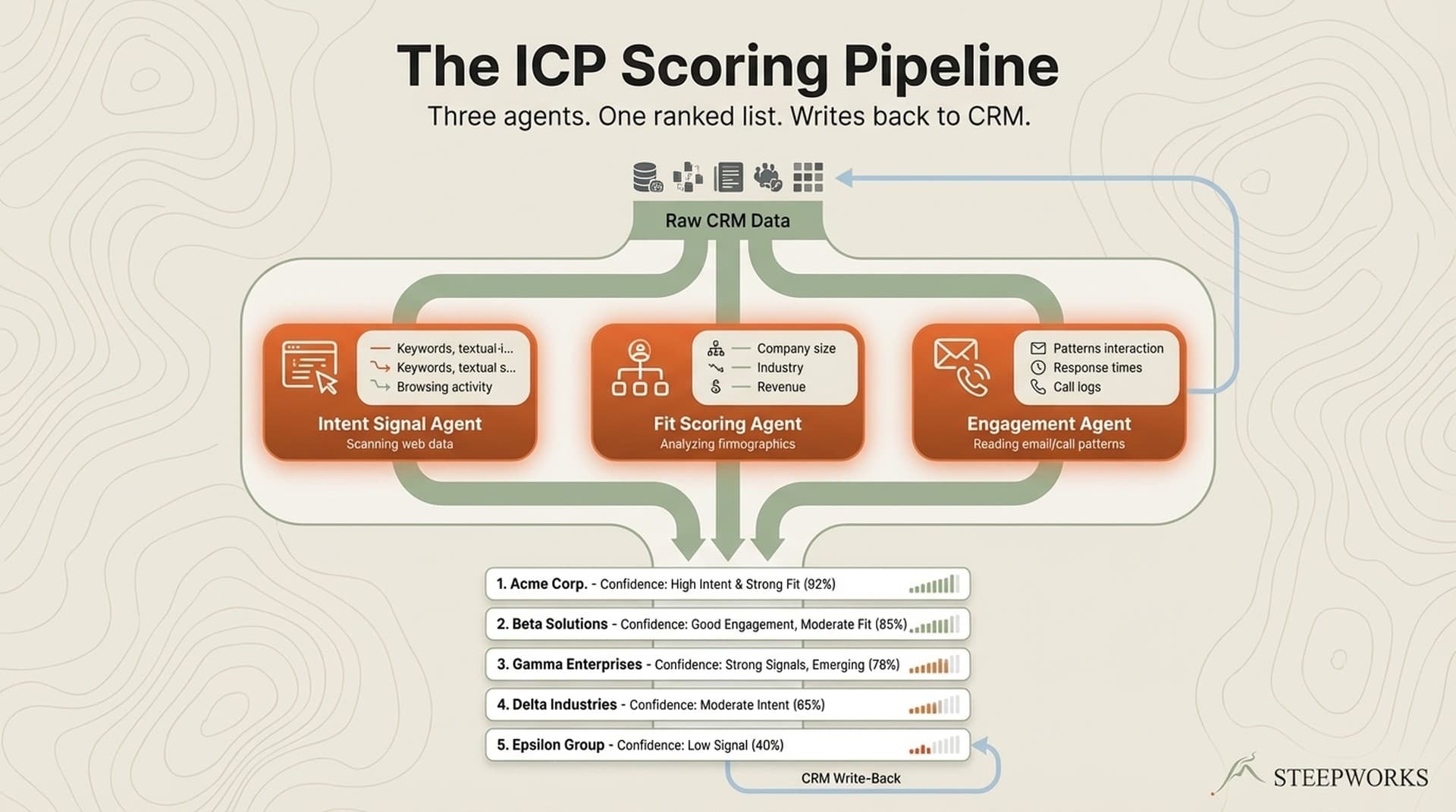
Agent 1: Evidence Collector (the research-prospect skill)
- Queries CRM for deal history and competitive mentions
- Searches web for recent news, product updates, pricing changes
- Documents all findings with source attribution and access dates
- Explicitly instructed: "This is an evidence collection exercise. Do NOT score, rank, or interpret findings."
- Output: structured evidence document with provenance tags
Agent 2: Positioning Analyst (the competitive-positioning skill)
- Reads the evidence document as input
- Scores competitive threats based on documented criteria
- Generates positioning recommendations
- Produces battlecard content for sales enablement
- Can only work with evidence that Agent 1 surfaced (no independent research)
The constraint on Agent 2 is critical. If the positioning analyst can also search the web, it will. And it will find information that confirms whatever narrative it's developing, because that's what confirmation bias looks like in AI systems. By restricting its input to Agent 1's output, you force the interpretation to stay grounded in documented evidence.
Confidence Tiers: Making Uncertainty Visible
Not all competitive intelligence is equally reliable. A pricing quote your rep heard directly from a prospect is different from a pricing page screenshot, which is different from a G2 review mentioning pricing from 8 months ago.
Confidence tiers make this uncertainty visible in the output:
TIER 1: Verified. Multiple independent sources confirm. CRM data corroborated by public documentation. Direct observation (pricing page screenshot + deal notes mentioning the same price). Roughly 40% of competitive claims in a well-researched brief.
TIER 2: Single-source. One credible source, not independently verified. A single G2 review, one rep's deal notes, one news article. Accurate enough to use, but worth noting the limitation. Roughly 55% of claims.
TIER 3: Inferred. No direct source. Logical deduction from available evidence. "Their Q1 hiring suggests they're investing in enterprise sales" is inference, not evidence. Less than 5% of claims in a good brief, clearly labeled.
Every claim in the competitive brief carries its tier. Sales reps learn to treat TIER 3 claims as hypotheses, not facts. They stop presenting inferences as certainties in prospect conversations.
The tier distribution itself is diagnostic. If more than 15% of your brief is TIER 3, you don't have enough evidence to make confident claims. The right response is more research, not more confident language. I've seen teams compensate for thin data by writing more assertively. That's the opposite of what works.
Implementing Tiers in Claude Code
The evidence collector skill tags each finding with a tier at collection time: (done-for-you implementation)
**Pricing:** Enterprise tier starts at $85/seat/month [TIER 1: pricing page screenshot 2026-04-20 + confirmed in 2 closed-lost deal notes]
**Roadmap:** Planning to launch API marketplace in Q3 [TIER 2: single LinkedIn post from VP Product, 2026-03-15]
**Strategy:** Likely shifting focus to mid-market based on recent SMB customer churn reports [TIER 3: inferred from 2 G2 reviews mentioning reduced SMB support + job postings emphasizing "mid-market experience"]
The positioning analyst skill respects tiers in its recommendations. It won't build positioning around TIER 3 claims. It highlights when a key positioning angle relies on TIER 2 evidence that could be strengthened with additional sourcing. (pricing tiers)
Competitive Battlecard Generation
Battlecards are the delivery vehicle. Everything above is architecture. The battlecard is what the sales rep opens before a call.
The competitive intelligence workflow produces battlecards through a three-stage pipeline:
Stage 1: Evidence collection. CRM-first research, web supplementation, confidence tier tagging. Output: raw evidence document. Duration: 3-5 minutes of elapsed time.
Stage 2: Analysis and positioning. Threat scoring, positioning recommendations, differentiation angles. Output: strategic analysis. Duration: 2-3 minutes.
Stage 3: Battlecard formatting. Sales-ready format with quick-reference positioning, objection responses, trap questions, and proof points. Output: competitive battlecard. Duration: 1-2 minutes.
Total pipeline: 6-10 minutes from trigger to finished battlecard. The manual equivalent, done properly with CRM research and source verification, takes 4-6 hours.
What a Good Battlecard Contains
After testing 20+ battlecard formats with 3 different sales teams, here's what reps actually use:
Section 1: Quick Positioning (used in 90%+ of calls)
- One-sentence differentiator
- "When they say X, we say Y" response pairs
- 3 proof points with named customers or metrics
Section 2: Trap Questions (used in ~60% of calls)
- Questions to ask the prospect that expose competitor weaknesses
- Each question tied to a specific evidence-backed vulnerability
- Phrased as genuine discovery questions, not gotcha traps
Section 3: Objection Responses (used situationally)
- Top 5 objections from CRM win/loss analysis
- Each response with evidence citation
- Confidence tier visible so rep knows how assertively to deploy
Section 4: Evidence Appendix (rarely referenced directly)
- Full evidence document with provenance tags
- Useful when a prospect challenges a specific claim
- Rep can say "here's where that came from" with a source
Sections 3 and 4 are there for when you need them. Sections 1 and 2 are what reps memorize.
Freshness and Staleness Handling
Competitive intelligence has a shelf life. A battlecard from 6 months ago is worse than no battlecard because it creates false confidence.
The system handles freshness at two levels:
Data level: Every sourced claim carries an access date. The evidence collector flags claims older than 90 days as potentially stale. CRM data is timestamped to the deal close date. Web data is timestamped to access date.
Battlecard level: Each battlecard has a generated date and a recommended refresh date (default: 30 days for active competitors, 90 days for monitoring-tier competitors). A weekly scan identifies battlecards past their refresh date and queues them for re-generation.
In practice, we refresh battlecards for our top 3 competitors monthly and the rest quarterly. The refresh takes 10 minutes per competitor because the pipeline re-runs against fresh data. That's 30 minutes per month for up-to-date competitive positioning against our primary competitive set.
Measuring Research Quality
Three metrics tell you whether the competitive intelligence system is working:
1. Confidence tier distribution. Healthy distribution: 35-45% TIER 1, 50-55% TIER 2, less than 10% TIER 3. If TIER 3 creeps above 15%, your sourcing needs improvement. If TIER 1 is below 30%, your CRM data capture process is likely weak.
2. Sales usage rate. Track how often reps reference competitive positioning in call notes or deal updates. Before the system, our competitive positioning usage rate was roughly 25% of deals with known competitors. After: 72%. The increase came from making battlecards accessible and trustworthy, not from mandating their use.
3. Contamination detection rate. The edit pass (analogous to the edit-content skill for competitive briefs) checks for interpretation leaking into evidence sections. Track how many instances it catches per brief. The number should decrease over time as your upstream prompts improve. Ours went from an average of 4.2 contamination instances per brief to 0.8 over three months.
Setting Up the Full Pipeline
Here's the implementation order, from fastest value to full system:
Week 1: CRM-first evidence collection. Configure the research-prospect skill with your CRM connection. Run it against your top 3 competitors. Verify the CRM data is pulling correctly. This alone produces better competitive research than web-only approaches.
Week 2: Add confidence tiers. Update the evidence collection to tag every claim with TIER 1/2/3. Review the tier distribution. Identify gaps where you're relying heavily on TIER 3 inferences and plan targeted research to fill them.
Week 3: Build the downstream positioning skill. Configure the competitive-positioning skill to consume evidence documents and produce analysis. Test the separation by checking whether the evidence document reads as neutral reporting. If it doesn't, tighten the upstream prompt.
Week 4: Battlecard generation and distribution. Set up the battlecard formatting stage. Generate battlecards for your top competitors. Get feedback from 2-3 reps. Adjust the format based on what they actually reference.
Ongoing: Freshness automation. Set up the weekly staleness scan. Configure refresh cadences per competitor tier. Budget 30-60 minutes per month for battlecard maintenance.
The full pipeline is operational in about a month. Each week delivers standalone value. You don't need the complete system to start getting better competitive intelligence from Claude Code.
Frequently Asked Questions
What CRM integrations does Claude Code support for competitive intelligence?
Claude Code connects to CRMs through MCP (Model Context Protocol) server integrations. HubSpot, Salesforce, and Monday.com all have working MCP integrations. If your CRM has a REST or GraphQL API, an MCP server can be configured for it. The CRM-first research protocol gracefully degrades when CRM access isn't available, falling back to web sources with a note that CRM data was unavailable.
How does this compare to dedicated competitive intelligence platforms like Klue or Crayon?
Klue and Crayon are purpose-built for competitive intelligence with features like automated monitoring, alert systems, and sales enablement integrations. They're strong products for teams that need a polished, dedicated CI platform. Claude Code's advantage is architectural flexibility and integration with your broader GTM workflow. Your competitive research feeds directly into meeting prep, content production, and deal strategy without switching tools. The tradeoff: more setup time, less polished UI.
How do I prevent the AI from hallucinating competitive claims?
Three mechanisms work together. First, the CRM-first principle grounds research in your own verified data. Second, confidence tiers make uncertainty visible instead of hiding it behind confident language. Third, the upstream/downstream separation prevents interpretation from contaminating evidence. No system eliminates hallucination entirely, but these three layers reduce it from "common and invisible" to "rare and labeled."
How often should competitive battlecards be refreshed?
For your top 3 competitors (those appearing in 60%+ of competitive deals): monthly. For your monitoring tier (competitors you see occasionally): quarterly. For emerging competitors you're tracking: when triggered by a significant event (funding round, major product launch, pricing change). The automated freshness scan catches battlecards past their refresh date and queues them for regeneration.
Can non-technical team members use this system?
The battlecard output is a markdown or PDF document that anyone can read. The pipeline itself runs through Claude Code, which requires basic familiarity with triggering skills. In practice, one person on the team (usually an ops or enablement role) runs the pipeline, and the outputs are distributed to the broader sales team through existing channels like Slack, email, or your sales enablement platform.
What's the minimum data requirement in the CRM for this to work?
You need competitive mentions in deal records. Specifically: competitor names in a structured field (not just buried in notes), and ideally win/loss reasons that reference specific competitors. If your CRM has 50+ closed deals with competitive data, the system produces meaningful intelligence. Below that threshold, web sources carry more weight, and you should focus on improving CRM data capture as a parallel workstream.