title: "What It Actually Takes to Write Good AI Copy" slug: what-it-takes-good-ai-copy author: Victor Sowers type: article domain: steepworks status: published target_platform: linkedin target_word_count: 2200 date: 2026-05-05 updated: 2026-05-05 description: "The real workflow behind AI-assisted content that doesn't read like slop — skill chains, editorial passes, and why inline drafting always fails." tags:
- ai-content
- content-production
- anti-slop
- operator-practice
- claude-code
What It Actually Takes to Write Good AI Copy
I run 3+ newsletters across 3 different domains. I produce 4-8 distinct pieces a week, most of them over 3,000 words. That's a volume I couldn't have touched before. It is absolutely AI-fueled.
And to get it to a place of generating value for you as a reader while amplifying but not replacing me as a writer/editor/producer, well, that has been a long and ongoing process.
AI slop comes in many forms. My journey began with a less obvious form of AI slop:
- Generated filler that sounds authoritative but says nothing specific
- Hedging language that diluted every claim
- Paragraphs that existed to serve the article's structure rather than the reader's understanding
- Headlines that sounded like every other AI-generated headline on LinkedIn
- Content that passed Grammarly at 98 but said nothing a competitor's ChatGPT couldn't also say
I built a system to fix that. Because well-crafted AI-enhanced writing requires a robust system that works with you on multiple different dimensions that extend well beyond good prompts.
Layer 1: Have a (human) opinion
AI cannot originate the thesis.
It can research. It can draft. It can restructure and edit and polish. It can regurgitate. It can synthesize - and do it well if guided with a good prompt - but it isn't at the point of originality. Far from it. I mean hell, it can't catch itself writing "It's worth noting" for the third time in a single draft yet.
The input that matters most is lived experience. A failed experiment. A pattern you noticed, some idea sticking with you for whatever reason.
If you're using AI to write content and you're not starting with a specific nugget you're heading down the path of generating filler at scale.
Layer 2: Give it interesting context
Instead of a specific thesis or angle, most people give their AI a topic and expect quality. That's like throwing someone into a kitchen with a chaotic mix of ingredients and expecting a coherent dinner. What you'll get instead is the reheated frozen served perfectly on time.
But what makes context interesting? First it means material the model wouldn't have without you providing it:
- Your call transcripts
- Your product analytics
- Your competitor's latest pricing page
- Your actual voice and perspective — for example giving it the interview you recorded with your CTO
On top of engineering the context that frames the AI's assignment, interesting content emerges when you tie strands together around potentially disparate content. For example, I'm giving you these ten things, and here's why, and here's some sense of why I think they're connected or what I found interesting about them and I want you to be a thought partner in finding the thread.
Another method here that tends to generate good results is about laddering context and content over time. For example, ongoing synthesis of call recordings with instructions to look at changes over time and compare that to product roadmap + industry news, or sitting on top of agents that are continuously mining certain patterns (e.g. we publish a weekly newsletter tracking an entire sector, if we look back at it on a quarterly basis, letting the AI explore what was most interesting is a good way to generate those nuggets of insight to shape a specific content piece).
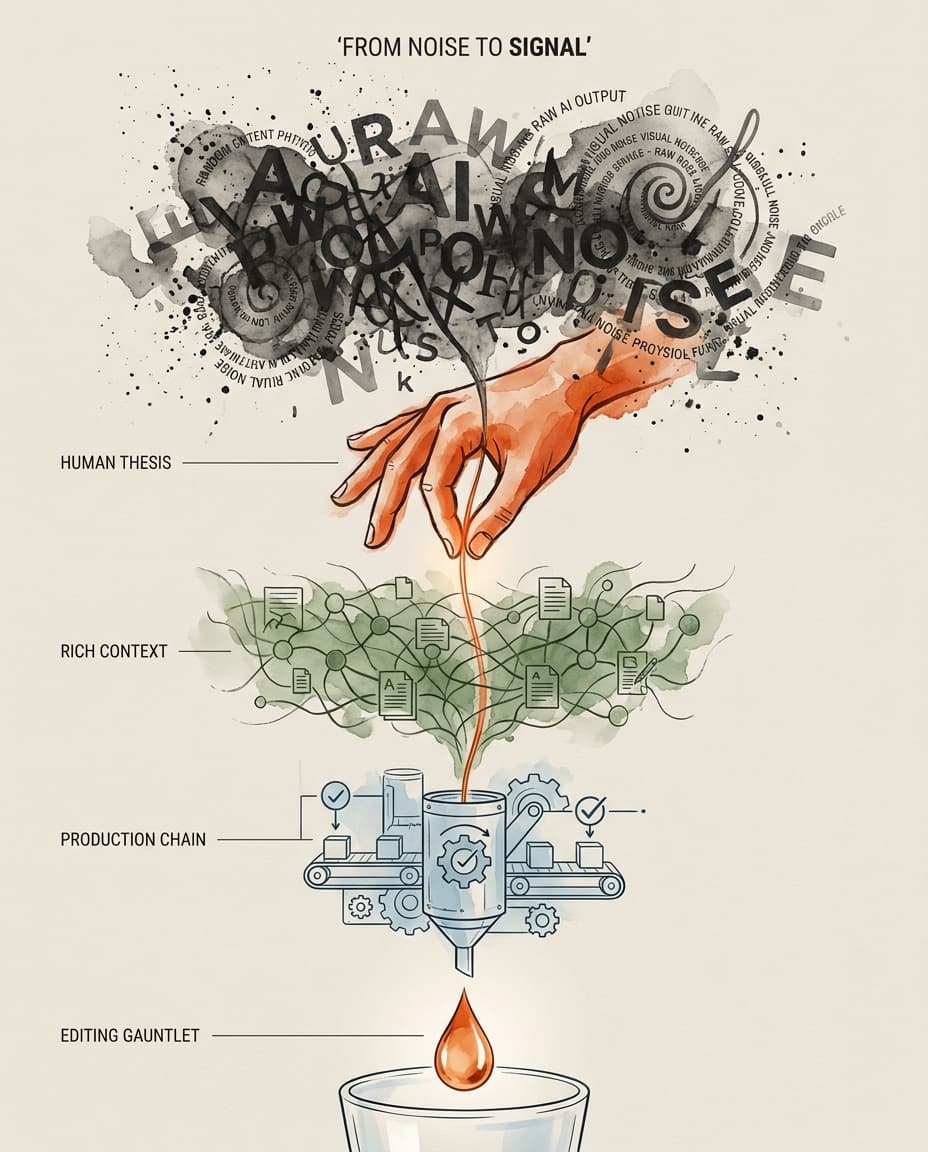
Layer 3: The Production Chain
Once you have a thesis and the raw ingredients that might make it interesting, the next step is to develop a robust process to guide the AI to (1) find interesting stuff, and (2) write about it like YOU not like every other piece of LLM generated content.
One disclaimer here: there's a real pull to just let the AI go write something, but I'd strongly suggest not letting it one-shot a fully formed piece of content. You get better results with defined human-in-the-loop moments where you can steer and redirect rather than coming back in at the end to try and salvage someting. The trick is productizing that process enough to still get some scale out of it. (professional Claude Code implementation)
Without more preamble, here's the STEEPWORKS content pipeline chain:
Stage 1 — Shape. Most people skip this entirely. They hand the AI a topic and say "write me a blog post." The outline is the highest-leverage moment in the entire chain because redirecting here costs minutes. Redirecting after a full draft costs hours. Measure twice, cut once and all that.
Practically I have the LLM generate 3-5 angles for every piece, each with a specific rationale grounded in the research context and interesting insight I've already gathered. Often I'll end up asking it to combine and mix and match aspects of each.
Then I build a structured outline: 5-7 sections, each with a purpose statement, key points, evidence slots, and a word count target. Not "Introduction" and "Conclusion." Each section earns its place by answering what it's proving and what evidence backs it up. (free setup guide)
The outline gets explicit human approval before a single word of draft is written. This is the gate. A well-structured outline with clear section purposes produces dramatically better drafts than a vague topic paired with good writing instructions. Sounds obvious because it is.
Stage 2 — Produce. The drafting process starts by loading your tone of voice document as well as a 170-line voice standards document before the first word is written. The standards doc isn't saying something like "write in a professional tone." It's filled with specific do/don't pairs: DO "85% adoption rate," DON'T "Revolutionary solution."
There are hard and fast rules, and more importantly there are dozens of before/after examples of past rewrites and edits. These example passages give the model has something to pattern-match against rather than guess.
Three examples from the principles that do the most work:
"Trust the reader." If two numbers tell the story, don't add commentary. "12-15 anti-slop violations per draft six months ago. 3-4 now." That IS the argument. Adding "this shows the system is clearly working" is like adding "this is funny" after a punchline.
"Practitioner solidarity." Write "we are all building these workflows from scratch" instead of "teams face growing challenges with AI content." First-person plural creates "we're in this together." Third-person creates distance.
"Cause-and-effect over abstract framing." Never write "X exposed the paradox facing content operators." Write "there's more content to produce, AI drafts it faster, so the editing bottleneck moves downstream." Simple causal chains beat conceptual labels.
(Those training examples are also the seed for a universal principles document that constantly evolves to further guide the AI on how you want it to sound and behave).
Stage 3 — Review. From a draft and before the human comes back into the loop, we launch four AI agents to run in parallel:
- Two editorial compliance agents (redundancy catches what one misses) that focus on AI anti slop principles (mechanical and constructive)
- A narrative and clarity focused agent
- An evidence validator that checks every number against source files — plausible but made up is a dangerous, hard-to-catch failure mode of AI generated content
The editorial agents run against 40+ anti-slop patterns across four categories, each with a different detection method. I wrote about this in detail, but the short version:
- Banned Phrases get caught by automated search: "It's worth noting" gets removed on sight because the sentence after it is always stronger without it.
- Structural Patterns get caught by visual scan: em-dash saturation is the single most recognizable AI tell (models use them at 3-5x the human rate).
- Voice Violations get caught by judgment read: "Unlock the secrets to..." is guru language that breaks practitioner solidarity.
- Content Sins get caught by editorial skepticism: "Companies see a 47% improvement" with no source and no methodology is content-grade hallucination.
Each finding goes through a confidence scoring system. High-confidence safe edits get applied automatically. Everything else gets flagged for human review.
Stage 4 — Edit. Depending on the content, I'll either come back in at this stage or launch a copywriting pass. This is a specific skill that takesthe principles of 13 copywriting masters and uses them as diagnostic lenses that ask a different question of the copy. Hopkins asks "Can I add a specific number? Is this claim testable?" Ogilvy asks "Is my headline doing 80% of the work?" Provost checks rhythm and flags any run of three or more consecutive sentences at similar length.
The edit phase has a specific emphasis on subject lines, headlines, and section headers too. These get run through seven specific tests. For example, Test 3 is the "So What" test. Something like "our platform uses AI-powered analytics" fails whereas "we surface insights you'd miss manually so you make better decisions in half the time" passes.
As one example, I edited one STEEPWORKS article from 3,857 words to 2,192. A 43% cut. From that I extracted 10 before/after pairs from that edit as training data. It generated one meta rule: remove anything serving the article's structure. Keep anything proving operator practice
Stage 5 — Skeptical Buyer. The skeptical buyer is a skill launched in a clean context window (and often using an entirely different model) that acts like your target audience persona (e.g. a simulated buyer in your ICP with a specific title, specific company, specific current tools, specific use cases). This agent attacks your content from three angles:
- Plausibility — do I believe this?
- Prioritization — is this worth my time over the 50 other things on my list?
- Differentiation — why this and not the thing I'm already using?
The content has to survive all three.
More broadly, cross-model adversarial review is one of the most underrated techniques. Claude drafts the content. Gemini critiques it. Each model has different blindspots. If both flag the same issue, it's definitely worth thinking about. If they disagree, that's where the interesting structural questions live and you might come up with even more interesting insights.
Why build a chain like this? A single prompt, even single context windows can't hold voice standards, anti-slop rules, buyer psychology, editorial principles, and competitive context simultaneously. Each stage loads only the context it needs.
The System Compounds
Every layer uses AI. But at every layer, human judgment sets the standard and evaluates the output. And the layers feed each other: editing catches become context for future drafts. Anti-slop patterns that showed up 12-15 times per draft six months ago now show up 3-4 times. That happens because the context got richer.
The thesis, the context, and the production chain combined with solid prompts form the cornerstone of a strong AI content pipeline.
But you don't need 19 AI skills to start. The minimum viable version: write your thesis by hand before you prompt anything. Build a voice document with 10 do/don't pairs and load it into every session. After each draft, read it aloud and make your own edits. Then have the AI come in behind you and learn from what you did, gradually building out YOUR process (because, if it's not yours, why are you even doing it).



