title: "The 7-Skill Content Chain That Produces 3 Newsletter Editions Per Week" slug: 7-skill-content-chain seo_keyword: "AI content chain" meta_description: "AI content chain: 7 skills produce 3 newsletter editions weekly from 313 event sources. Full pipeline from ingestion to quality gate to send." og_description: "A production buildlog of the 7-skill content chain running 3 weekly newsletters across different brands. The architecture, the skill-to-skill handoffs, why order matters, and the multi-brand voice problem nobody talks about." cluster: content-operations author: Victor status: published published_date: 2026-03-26 read_time_minutes: 13 description: "The 7-Skill Content Chain That Produces 3 Newsletter Editions Per Week" domain: steepworks type: article updated: 2026-03-26
The 7-Skill Content Chain That Produces 3 Newsletter Editions Per Week
The Newsletter That Broke When I Added a Second Brand
The first newsletter ran fine for months. A monolithic script that scraped events, evaluated them, drafted copy, and published. One prompt chain, one audience. Shipped every week.
Then I added a second brand -- different region, different audience. The monolith collapsed in two weeks. Different voice, different event criteria, different review standards, same pipeline. Every change to one brand broke the other. The scraper knew about the voice. The evaluator assumed a single audience. The draft template was hardcoded. No contract between stages -- just one long prompt doing everything in a single pass.
Tight coupling. Not a tool failure. Not a model failure. An architecture failure.
Most AI content operations articles describe sequential steps -- research, draft, edit, publish -- as if automating each step is the hard part. It isn't. The hard part is the interfaces between steps. What one skill promises the next. How you swap a component without rebuilding the pipeline. How you add a second brand without rewriting the first.
This pattern applies anywhere you produce recurring content across multiple audiences -- newsletters, blog programs, email nurture sequences, sales enablement libraries. Newsletters happen to be where I hit the wall first, but the architecture is audience-agnostic. If you manage a blog, a customer email sequence, and a partner newsletter from the same content operation, you already have this problem.
By "skill," I mean an independently testable software module with a defined input and output -- not a human capability or a job title. A skill can be a prompt, a script, a configured tool, or a custom function. What makes it a skill is that you can run it in isolation and verify its output before connecting it to the chain.
This is a buildlog of the 7-skill content chain I run in production. Not 7 tools strung together, but 7 composable skills with defined input/output contracts. It produces 3 newsletter editions per week across different brands. I'll show the architecture, why order matters, what the handoffs look like, and the multi-brand voice problem that 71% of marketers now scaling their AI content workflows aren't talking about.
Why Skills, Not Steps -- The Composability Principle Behind the Chain
When your newsletter draft fails at 2am before a morning send, can you identify which stage broke? When you add a second brand next quarter, do you reconfigure one component or rebuild the pipeline? When your email platform changes its API, does it ripple through your drafting logic?
These are composability questions, and the answers determine whether your AI content operations scale or calcify.
A "step" is a position in a sequence. A "skill" is an independently testable module with a defined input contract, output contract, and quality standard. The difference matters when you need to swap one component, add a new brand, or debug a failure on deadline.
Three properties make a skill composable:
- It can run in isolation with sample inputs. You can feed the classify skill a test batch and verify it tags correctly without running the scraper first.
- Its output format is a contract the next skill can rely on. The evaluate skill always produces scored records with per-evaluator reasoning. The draft skill knows exactly what it will receive.
- You can version it independently without touching the rest of the chain. Updating the classification taxonomy for one brand doesn't require changes to the draft skill for another brand.
This is the same upstream/downstream separation principle applied to content production: each skill describes reality for the next skill without assuming what the next skill will do with it.
Tools like Jasper's Content Pipelines automate individual stages well. But they assume a single content type and a single brand voice. The composability problem is what happens when the same architecture needs to serve family events in Baltimore, regional events across the DMV, and a B2B intelligence newsletter -- with different evaluation criteria, different voices, and different quality bars for each.
I call it a "chain" and not a "pipeline" for a reason. A pipeline implies linear flow. A chain implies each link depends on the strength of the link before it. If the scraping skill returns garbage, no amount of downstream brilliance saves the draft. Every link carries weight.
The 7 Skills in Order -- What Each One Does and Why It Exists
The full 7-skill chain took roughly 3 months of iteration alongside regular content production. But here's what matters for your planning: each skill is a config file and a prompt, not custom software. A content marketer comfortable with AI prompting can configure most of these. The scraping and publishing skills need light technical ability -- API calls, data formatting, scheduling. You don't need an engineer. You need an operator who thinks in systems.
Skill 1: Scrape
Collects raw event and content data from multiple sources. Output: structured records with source metadata, timestamps, and raw descriptions.
Why it's separate: scraping logic changes constantly. Sources add paywalls, change HTML structures, go offline. Isolating scraping means source failures don't cascade into evaluation failures.
The failure that created this boundary: when scraping was embedded in the evaluation step, a single broken source URL crashed the entire weekly run. Separating them meant a source going offline is a scraping problem, not a pipeline problem. The scraper returns whatever it can collect. The next skill handles what to do with an incomplete batch.
Skill 2: Classify
Categorizes and tags each record against a taxonomy -- event type, audience segment, geographic region, age range. Output: enriched records with classification metadata.
Why it's separate from scraping: classification rules are brand-specific. The same spring festival might be "family-friendly outdoor activity, ages 3-10" for one brand and "irrelevant -- wrong region" for another. Separating classification from collection lets you run different classifiers on the same scraped data without re-collecting anything. One scrape, three classification passes. The data enters once and branches at the classify stage.
Skill 3: Evaluate
Scores each classified record against brand-specific relevance criteria. Uses multi-agent evaluation where applicable. Output: scored and ranked records with per-evaluator reasoning.
Why multi-agent: a single evaluator develops blind spots within weeks. I watched it happen -- one agent developed recency bias within 3 weeks, consistently over-scoring trending topics and under-scoring evergreen content. The multi-agent architecture uses distinct personas to prevent consensus drift. Each persona scores from a different audience perspective, and their disagreements surface the borderline picks that matter most.
Across all 3 brands, the evaluate skill processes roughly 200+ records per week. The family events brands evaluate scraped event data. The B2B brand evaluates curated articles from 65+ RSS feeds. Different inputs, same skill architecture, different evaluation criteria per brand.
Skill 4: Debate
For the B2B intelligence newsletter: moderated multi-agent debate on borderline selections. For event newsletters: threshold-based triage with human override. Output: final selection set with debate transcript or triage rationale.
Why debate is separate from evaluation: Evaluation answers "how relevant is this?" with a score. Debate answers "should we include this?" with reasoning. The difference matters. In one production week, evaluation ranked a trending-but-shallow AI tool announcement as the #2 pick across all evaluators. Debate surfaced that three of five evaluator personas rated it high for novelty but low for depth -- the article had no implementation guidance, no failure analysis, no production data. It scored well because it was new, not because it was useful. Debate caught what scoring missed: consensus without conviction.
Debate is optional per brand. Event newsletters use threshold-based triage -- records above a score threshold make the cut, borderline picks get human review. The B2B newsletter uses full moderated debate because the editorial bar is higher and the cost of including shallow content is steeper.
Skill 5: Draft
Generates newsletter copy from the selected content. Each brand has its own voice profile, template, and structural rules. Output: complete newsletter draft in brand-specific format.
This is where the monolith dies. Three brands means three voice profiles, three template structures, three sets of editorial rules. A monolithic drafter can't hold three voices without blending them. The draft skill loads a different voice context per brand run -- tone, vocabulary, structural preferences, audience assumptions. More on how this works in the next section.
Skill 6: Review
Quality gate that evaluates the draft against multiple dimensions: factual accuracy, voice consistency, structural compliance, audience appropriateness. Output: scored review with specific revision directives.
I've written about the evolution from single-agent to multi-agent curation. The review skill catches what Grammarly misses because it evaluates against your brand standards, not universal grammar rules. A draft can be grammatically perfect and still fail review because the voice drifted toward the wrong brand, or the age-range callouts are missing for a family events edition.
Review is not editing. Review produces a diagnostic -- what's wrong and why. Editing applies the fixes. Keeping these separate means the review skill can be honest without also being responsible for the fix. Revision feedback goes back to the draft skill or to a human editor. The review skill's job is diagnosis, not treatment.
Skill 7: Publish
Formats the reviewed draft for the distribution platform, handles scheduling, and triggers distribution. Output: published newsletter with delivery confirmation.
Why publishing is a skill: format requirements change when platforms update. Isolating publish means a platform API change doesn't require touching the drafting logic. The blast radius of a platform change is one skill, not seven. When the email platform updated its rendering engine last quarter, I updated one template file. The other six skills never knew it happened.
Maintenance Burden
Ongoing maintenance: 2-3 hours per month. Mostly scraper configs when sources change, plus occasional evaluation criteria tuning. The chain itself is stable. What changes are the brand-specific configs, not the architecture. Heaviest maintenance: Skill 1 (scraping), because external sources break unpredictably. Lightest: Skills 4-6 (debate, draft, review), because prompt-based logic rarely needs adjustment once calibrated.
One Pipeline, Three Brands -- How Voice Isolation Actually Works
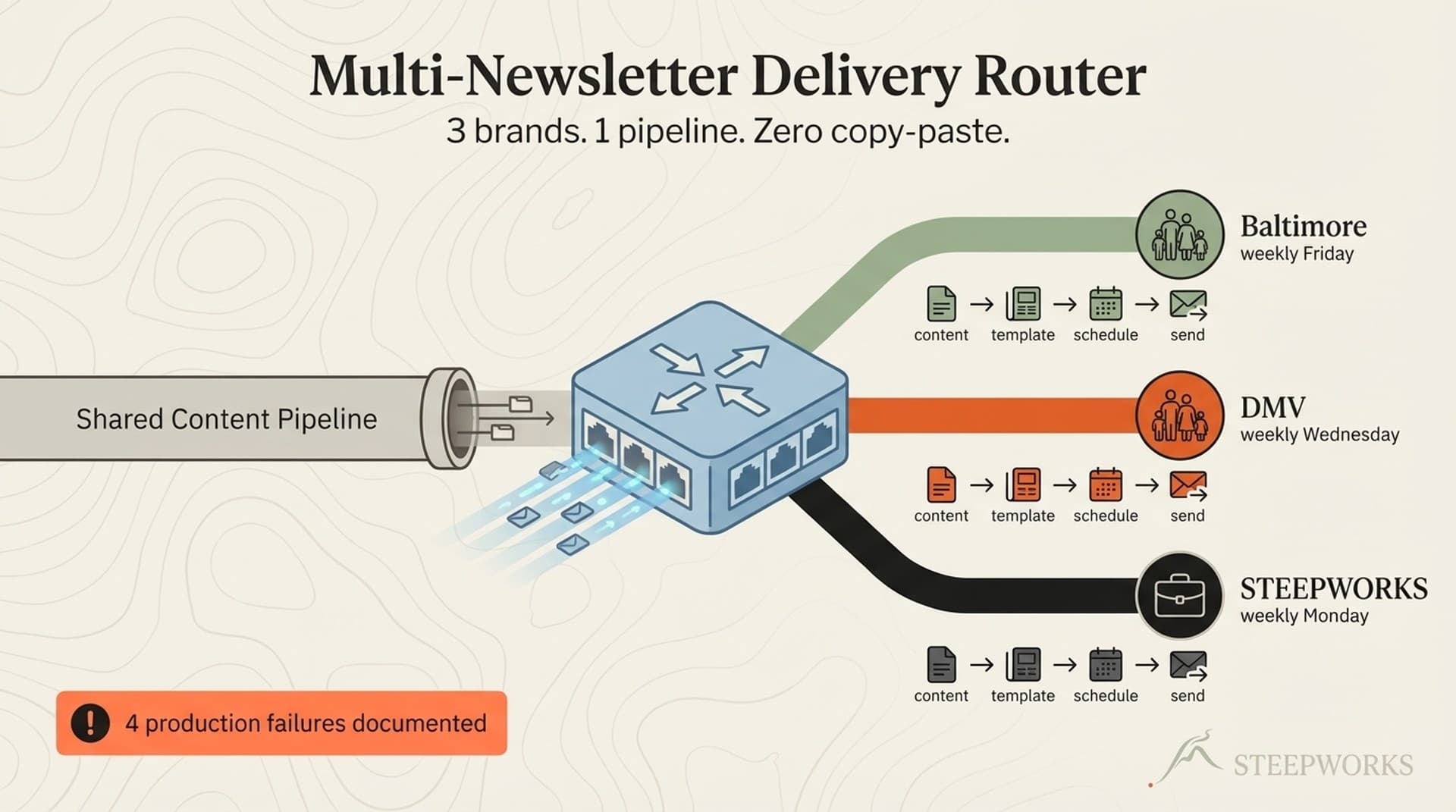
The three brands: a family events newsletter covering Baltimore, a regional events newsletter covering the broader DMV, and a B2B intelligence newsletter covering AI and go-to-market. Different audiences, different content types, different voices, different cadences.
What stays the same across brands: the skill chain architecture, the input/output contracts between skills, the orchestration pattern. The chain is the skeleton. Configuration is the muscle. (Claude for operators)
What changes per brand: voice profiles loaded at draft time, classification taxonomies loaded at classify time, evaluation criteria loaded at evaluate time, review standards loaded at review time, and publish targets loaded at publish time. Five of seven skills receive brand-specific configuration. Only scrape and the chain orchestration itself are brand-agnostic. (See also: newsletter pipeline)
Here's what voice isolation looks like in practice. Two of the three brands share the same upstream data (local events), but their draft skills load completely different voice contexts: (See also: content review agent)
Brand A (family events, Baltimore): Warm, practical, parent-addressing. Short paragraphs. Age-range callouts for every event. Safety and accessibility notes. Tone: "Your family's weekend starts here." Never uses jargon. Assumes the reader is planning a Saturday with kids under 12. Structural rules: lead with the weekend's top pick, group by age range, include free options prominently.
Brand B (regional events, DMV): Broader audience, editorial voice. Includes cultural events, seasonal activities, day trips across the metro area. Tone: "Worth the drive." More descriptive, less prescriptive. Assumes the reader is exploring options, not filling a weekend schedule. Structural rules: lead with the standout event, organize by geography and theme, include drive-time context.
Brand C (B2B intelligence): Reflective operator. Systems thinking. Anti-hype. Shows what broke, not just what worked. Assumes the reader is a GTM professional evaluating tools and workflows for their team. Structural rules: thesis-led, evidence-dense, includes the "what to ignore" framing for each section.
Same event data feeds Brands A and B. A spring festival in Baltimore might appear in Brand A ("great for ages 4-10, free parking, bring sunscreen") and Brand B ("a regional tradition worth the trip from Northern Virginia") but never in Brand C. The classify and evaluate skills filter by brand; the draft skill shapes by voice. (Knowledge OS guide)
The design pattern: brand context is injected as configuration, not hardcoded into skill logic. Each skill reads a brand config that tells it how to behave for this specific run. Same code, different context. This is the one-source-many-outputs principle applied at the skill level.
If you're running one newsletter, you don't need this architecture. But the moment you add a second brand -- or even a second content type within the same brand, like a weekly roundup and a monthly deep-dive -- the monolithic approach becomes a liability. Every brand addition should be a configuration change, not a rewrite. The second brand took me three days to add. A monolith rewrite would have taken three weeks.
Production output: 3 editions per week across the 3 brands, running consistently for the past 4 months. The chain handles the heavy lifting. I handle the judgment calls.
What Broke -- Three Failures That Shaped the Architecture
Every architecture is a scar tissue map. Here are the three failures that drew the most important boundaries.
Failure 1: Voice Bleed Across Brands
When one draft skill served multiple brands, the B2B newsletter started using casual family-event language -- "this weekend's top picks for your team" -- and the family newsletter started dropping GTM jargon -- "high-signal activities for the discerning family." It was subtle at first. A phrase here, a framing choice there. By week three, subscribers noticed.
A reply to the family newsletter: "Are you marketing to me or helping me?"
That reply cost more than any technical failure. It was a trust failure. The reader felt the voice shift before I did.
Voice isolation per brand -- separate voice configs loaded at draft time, with no shared context between brand runs -- eliminated the bleed completely. The fix wasn't complicated. The lesson was: a model holding two voice contexts in one prompt will blend them. Always. It's not a bug. It's how attention works. You have to enforce isolation at the architecture level, not the prompt level.
Cost of the failure: one week of mixed-voice sends before I caught it, and a handful of confused subscribers who needed to re-learn what the newsletter sounded like.
Failure 2: Single-Agent Evaluation Drift
One evaluator agent developed recency bias within 3 weeks. It consistently over-scored trending topics and under-scored evergreen content. The newsletter became a hype amplifier: every issue led with whatever was newest, regardless of depth or usefulness. I noticed when three consecutive issues opened with AI tool announcements that had no production evidence behind them.
The single agent wasn't broken. It was doing exactly what a single perspective does -- converging on its own patterns without friction. There was nobody to disagree.
Adding multi-agent evaluation with persona diversity fixed the drift. Each persona has different biases, and their disagreements surface the borderline picks that matter most. The Contrarian persona alone caught more shallow-but-trending picks in the first week than I'd caught manually in the previous month. Genuine editorial friction turned out to be more valuable than refined scoring rubrics.
Failure 3: Platform Coupling in Publishing
Hardcoding email platform formatting into the draft skill meant a platform formatting change broke every brand simultaneously. One API update on a Tuesday morning. Three broken newsletters before 9am. The formatting rules were embedded in the draft prompts -- font sizes, spacing, header styles, CTA button markup -- so the draft skill couldn't produce output without also knowing the platform's current requirements.
Moving platform-specific formatting to a dedicated publish skill contained the blast radius. Now a platform change is a publish-skill problem. The draft skill produces clean, structured content. The publish skill wraps it in whatever format the platform currently requires. When the email platform updated its rendering engine, I changed one file. Six skills upstream were unaffected.
The Pattern
Every failure was a coupling failure. Two systems that should have been independent were sharing assumptions. The skill chain exists because tight coupling creates cascading failures and loose coupling creates containable ones. You don't need to learn this lesson the hard way. But most of us do anyway.
Production Metrics -- What the Chain Actually Produces
I've been running the full 7-skill chain for 4 months. Here's what it actually produces, not what I projected it would produce.
Weekly production volume:
- 3 newsletter editions per week across 3 brands, every week, no misses
- 200+ source records scraped and classified per week
- 150+ records evaluated per week across all brands
- Average 8-12 curated items per family events edition, 6-8 per B2B edition
- Roughly 6,000 words of newsletter copy generated per week
Quality metrics:
- First-draft review pass rate: 72%. Meaning 72% of drafts pass the review skill without revision. The remaining 28% require one revision cycle -- usually voice consistency or structural issues, rarely factual errors.
- Average revision cycles before publish: 1.3. Most editions need one touch. Occasionally two. Never more than that.
- Voice consistency scores across brands: after implementing voice isolation, cross-brand voice bleed dropped to near zero. The review skill flags voice inconsistencies, and they now appear in fewer than 5% of drafts.
Subscriber engagement:
- Open rates range from 42-58% across the three brands, varying by content type and audience. The family events brands trend higher (readers have immediate weekend-planning intent). The B2B brand runs in the 42-48% range, which is strong for a GTM intelligence newsletter.
- Click-through rates average 8-14% across brands. Event newsletters drive higher clicks (readers click through to register or get details). The B2B brand generates lower CTR but higher reply rates -- readers respond to the analysis, not just the links.
- Subscriber growth has been steady since the chain went live, with the family events brands growing faster due to the local SEO pipeline feeding discovery.
Human time:
- I spend 4 hours per week on the human parts: reviewing debate outputs, approving final selections, reading each edition before publish, handling the occasional revision cycle. The chain handles roughly 20 hours of work autonomously -- scraping, classification, evaluation, debate, drafting, and formatting that would otherwise require a team of 2-3 people.
- Monthly maintenance: 2-3 hours, mostly scraper config updates and occasional evaluation criteria tuning.
Cost context:
- Infrastructure and API costs: under $200/month for all three brands. Model API calls, hosting, data storage. Equivalent freelance costs for 3 weekly newsletters at this curation and voice consistency level: $3,000-5,000/month minimum. The math isn't close.
Honest limitations:
- Breaking news responsiveness is weak. The chain runs on a weekly cadence. If something significant happens on a Thursday, the next edition is already in production. I handle breaking news manually when it matters.
- Opinion-driven content still needs human writing. The chain curates and structures well. It doesn't generate original analysis or hot takes worth reading.
- Visual design is manual. The chain produces text. Layout, images, and design live outside the chain.
- Original reporting and interviews are out of scope. The chain processes existing information. It doesn't create new information.
When You Don't Need This -- The Starter Architecture
You don't need a 7-skill chain if you run one newsletter on one topic for one audience. A well-prompted single agent with a human review pass is sufficient. Don't engineer complexity you don't have. A monolith works fine when you only have one thing to build.
You need this when you hit one of these triggers:
- You're adding a second brand or content type. The moment two audiences share upstream data but need different outputs, you need skill boundaries.
- A change to one part of your pipeline keeps breaking other parts. Coupling. The symptom is cascading failures. The cure is defined interfaces.
- You can't debug a quality failure because you don't know which stage caused it. If "the newsletter was bad this week" and you can't immediately point to whether the problem was bad sources, poor evaluation, voice drift, or platform formatting, your pipeline is a black box.
- You need different people to own different stages. A content marketer should own voice configs. A data person should own scraping. A product manager should own evaluation criteria. If one person has to understand the whole system to change any part of it, you have a monolith.
The 3-Skill Starter
Start with 3 skills: Collect, Draft, Review. That's it.
Collect: One prompt or script that gathers your raw material -- events, articles, data -- into a structured format. Define the output schema. Every record gets the same fields. This is your input contract.
Draft: One prompt with your voice profile that turns the collected material into newsletter copy. The voice profile is a separate document the prompt references, not inline instructions. This makes it swappable when you add a second brand.
Review: One prompt that evaluates the draft against your brand standards and produces specific revision notes. Not grammar checking. Brand standard checking. Voice, structure, audience appropriateness, and completeness.
Run this for 4-6 weeks. When you find yourself wanting to classify content differently for different audiences, add a Classify skill between Collect and Draft. When your single drafter starts blending voices, add voice isolation. When review keeps flagging the same types of issues, add an Evaluate skill upstream to filter earlier. The chain grows from operational pain, not architectural ambition.
For the VP Marketing at a Series B-C SaaS: your content marketer can configure the 3-skill starter in a day. The full 7-skill chain is what happens after 3 months of iteration. Don't start there. Start where the pain is. Add skills when the pain tells you to.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.