I've spent the last three months building an 8-chapter SEO playbook with a full AEO/GEO chapter, structured data on every key page, and an llms.txt file at the domain root. Then Google published their official AI Optimization Guide and told me most of it doesn't matter for their AI features.
So I ran an honest audit. steepworks.io against Google's new guide, line by line. 16 pages got semantic HTML changes. Two playbook chapters got rewritten. One component got enriched. And a few things I'd built with conviction got downgraded to "nice-to-have."
What the Guide Actually Says (Three Sentences)
Google's position is that AEO/GEO optimization is still SEO. No special files, no magic markup, no content chunking tricks. The guide says to focus on non-commodity content, technical health, and structured data for rich results. It adds one genuinely new concept: agentic experiences, where browser-based AI agents navigate your site's DOM structure to complete tasks on behalf of users.
That last part is the only thing in the guide that didn't exist in prior SEO guidance.
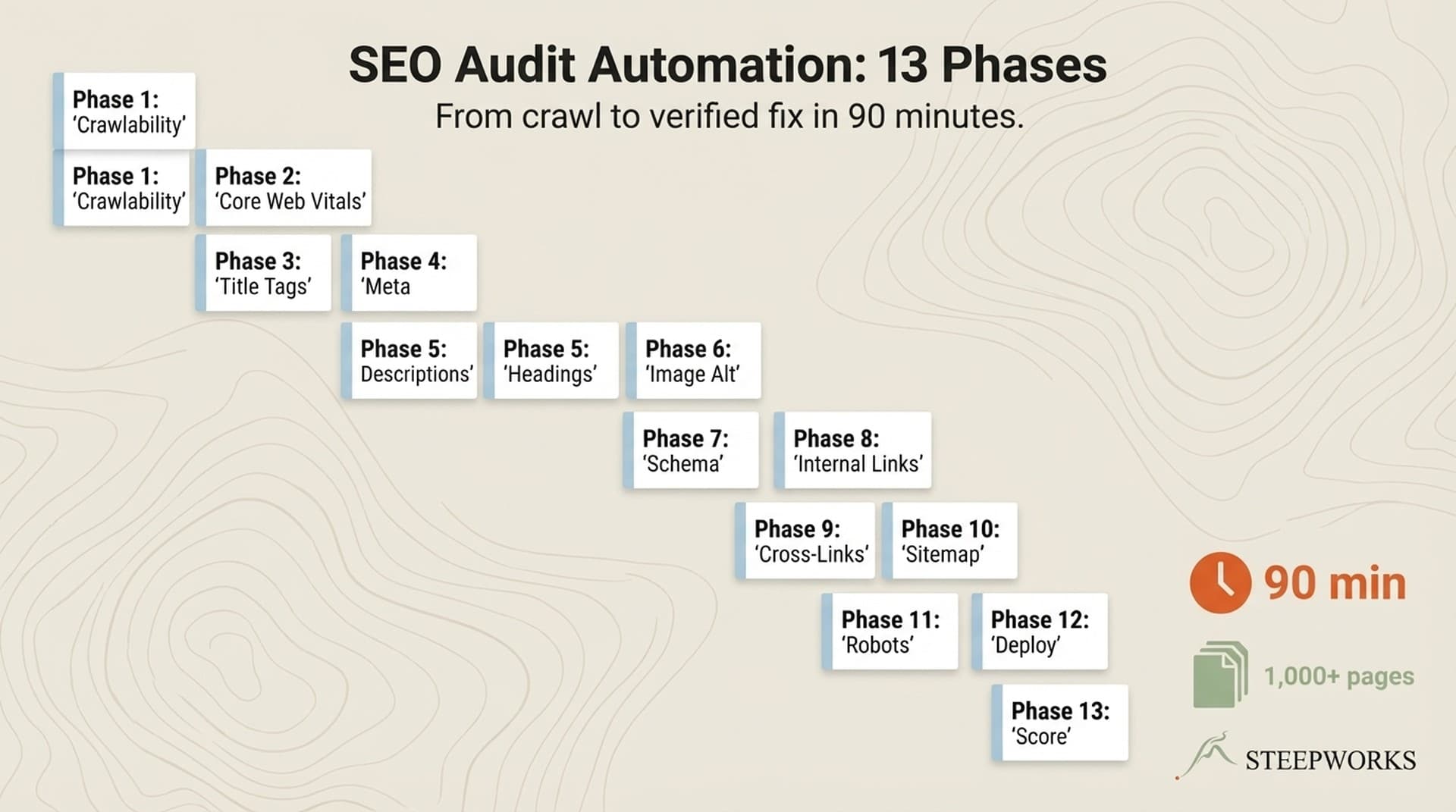
The Audit: 16 Pages, 2 Chapters, 1 Component
I organized the work into four categories: semantic HTML hardening, playbook chapter updates, author entity signals, and the practitioner article you're reading now. Everything happened in one afternoon with a PRD tracking each phase.
Semantic HTML: What Browser Agents Actually Read
The guide's section on agentic experiences changed how I think about page structure. Browser-based AI agents don't see your CSS. They read the DOM tree: <article>, <time>, <nav>, <section>. A page built entirely from <div> with Tailwind classes gives an agent nothing to work with.
I audited every content page on steepworks.io. The pattern was the same across article pages, guide pages, compare pages, newsletter archives, and glossary terms: content sitting inside <main> with <div> wrappers and no semantic signal that this was an article. No <article> element. No <time dateTime> on publication dates. The visible text said "May 21, 2026" but an agent parsing the DOM had no structured date to work with.
Two judgment calls worth noting. The compare hub at /compare I left alone because it's navigational, not article-like, and <main> with <section> is the right choice for an index page. And the SEO Playbook guide at /seo-playbook/guide was the trickiest case because the content uses dynamically imported chapter components and a table of contents, so the <article> wrapper had to span the full content region.
Total: 16 page templates changed across articles, guides, compare pages, newsletters, glossary, and one service page. No heading hierarchy violations found. The fixes were mechanical.
What to check on your site: Open your browser's dev tools on any long-form content page. If the first element inside <main> is a <div> rather than <article>, agents have no semantic signal. If your dates display as text without a <time dateTime=""> attribute, agents have no structured date. If your heading hierarchy skips levels (h1->h3), agents can't parse your content structure. These three checks cover 90% of the agentic readiness surface.
The honest assessment: I don't know whether this moves any needle. There's no metric for "agentic readiness." But the changes took about 45 minutes, they improve accessibility as a side effect, and they position the site for a direction Google is explicitly building toward. Low cost, asymmetric upside.
Playbook Chapter Rewrites: Correcting What We Got Wrong
Chapter 7 (AEO/GEO) of the SEO playbook needed the biggest update. I'd written it with conviction about llms.txt, structured data for AI features, and content formatting patterns for AI citations. Google's guide validated some of it and corrected the rest.
llms.txt: Downgraded from "implement this" to "if you have one, keep it." Google confirmed that their AI features (AI Overviews, AI Mode) don't use llms.txt. They rely on standard crawling and indexing. I'd positioned it as a tactical quick win. It's not, at least not for Google. Non-Google AI systems (Perplexity, ChatGPT, Claude) may reference it, so I didn't remove ours. But the chapter now says what it should have said from the start: nice-to-have, not must-have.
Structured data: Corrected the scope of its influence. The original chapter implied structured data (JSON-LD) helped with AI Overviews. Google's guide clarified that structured data helps rich results (review stars, FAQ dropdowns, product info in traditional search) but does not directly influence AI Overviews or AI Mode. The entity signals are still valuable. They give all search systems cleaner data about your brand, products, and people. But the AI features claim was wrong and I corrected it.
Agentic experiences: Added a new section that didn't exist. The original Chapter 7 had five sections covering brand tracking, llms.txt, robots.txt, content patterns, and comparison pages. I added a sixth covering semantic HTML, accessibility as agent-readability, clean form patterns, and the anti-patterns that block agent navigation (infinite scroll, JS-only interactions, CAPTCHAs on informational pages).
Chapter 8 (Operating Cadence) had a smaller change. The quarterly activities table listed llms.txt updates as a standalone task. I annotated it as optional, per Ch7's new framing. Keeps the cadence accurate without removing it for operators who already have one.
Both chapters live in two places (the website content directory and the products directory). Synced both copies.
Author Entity Signals: PersonSchema Enrichment
This one wasn't prompted by the guide directly. Structured data for rich results has always mattered, and our PersonSchema component was underbuilt. It had name, url, jobTitle, and worksFor. That's the minimum.
I added two properties:
sameAslinking to LinkedIn for entity disambiguation and Knowledge Panel eligibilityknowsAboutwith explicit topic signals: Claude Code, AI GTM, B2B SaaS, Knowledge Operating System, Go-to-Market Strategy, AI Agents
E-E-A-T reinforcement, basically. The schema tells Google what this person knows, which strengthens author credibility signals across the site. The component now renders on /about as a JSON-LD script tag. No visible UI change.
What We Kept
Not everything needed fixing. Some things I'd built before the guide landed were validated, which is the more useful signal. It tells you what to keep doing.
FAQ sections stay. They map directly to question-answer retrieval patterns. An FAQ with well-written questions gives AI systems discrete, citable pieces of information.
Comparison tables stay. "X vs Y" comparison pages serve traditional SEO (high commercial intent keywords) and AEO simultaneously. A genuinely useful comparison is harder to commoditize than a generic how-to, which is exactly what Google means by "non-commodity content."
llms.txt stays on the site. Google doesn't use it, but removing it would be premature. Perplexity, ChatGPT, and Claude may reference it. The file takes 2 minutes to update quarterly and costs nothing to maintain.
Brand mention tracking stays. The monthly brand_mention_tracker.py run that tracks web co-occurrence of "STEEPWORKS" alongside target categories is still the best proxy metric for AI brand association. The guide didn't address it directly, but didn't contradict it either.
Content-first strategy stays. The guide's central thesis (non-commodity content, technical health, traditional SEO fundamentals) validated the playbook's entire approach. Chapters 1-6 covering keyword research, clustering, content production, and backlinks are Google-confirmed as the primary optimization lever for AI features.
What We're Ignoring
We didn't build a GEO tracker. Chapter 7 describes a DIY tracker that queries multiple LLM APIs to check whether your brand appears in AI responses. $10-30 per run in API costs, advanced project. We marked it optional and moved on. Manual quarterly testing (open ChatGPT, Claude, and Perplexity; ask about your category; check if you show up) gives you the signal for free.
We didn't restructure content for "AI-friendliness." Some SEO advice post-guide has suggested rewriting content to be more "extractable" by AI systems. The guide says the opposite: focus on content nobody else can write. Writing for extraction is writing for commodity. We're writing for operators who deploy these systems, and the content's value comes from the specificity of the practice, not the format of the prose.
We didn't add special AI-related markup. No custom meta tags for AI crawlers. No "AI summary" blocks at the top of articles. No schema types beyond what standard SEO already uses. Google's AI features use standard crawling and indexing. If there's a trick, they didn't share it.
The One New Thing Worth Building For
Agentic experiences. Browser-based AI agents that can navigate websites, fill forms, compare products, and complete tasks on behalf of users. Not by reading a summary of your page, but by interacting with your actual DOM.
AI Overviews summarize content. Traditional crawling indexes pages. Agents do neither. They interact with your site the way a user would, except they read semantic HTML and accessibility signals instead of visual layout.
What this means practically:
- Semantic HTML matters more than it has in years. Agents parse
<article>,<nav>,<time>,<section>to understand page structure. Div soup with Tailwind classes gives them nothing. - Accessibility is agent-readability. ARIA labels, alt text, heading hierarchy, form labels. That accessibility audit you've been deferring is now also an AI optimization task.
- Clean form patterns matter. Inquiry forms and booking flows need semantic
<form>,<label>, and<input>elements. Custom div-based components don't register. - Infinite scroll, JS-only interactions, and CAPTCHAs on informational pages block agents. They always blocked accessibility. Same principle, new stakeholder.
The investment is mostly a one-time technical audit, not an ongoing cadence item. Check your key pages for semantic HTML. Fix heading hierarchy issues. Make sure forms are properly labeled. Most modern frameworks (Next.js, Astro) generate decent semantic HTML by default, but custom components tend to regress into div soup.
That's what our 16-page audit was: checking every content template for proper semantic elements and fixing the gaps. Not because we measured an immediate traffic impact, but because the direction of travel is clear and the cost of preparation is low.
If You're Running an SEO Playbook
The guide confirmed what our playbook already assumed. 80% of AEO/GEO optimization is traditional SEO. The keyword research, clustering, content production, and backlink work in Chapters 1-6 are the primary lever. The remaining 20% is now clearer than it was before the guide dropped:
- Semantic HTML readiness for agentic browsers. One-time audit.
- Author entity signals via PersonSchema and structured data. One-time build.
- Brand mention tracking as an AI visibility proxy. Monthly, 5 minutes.
- llms.txt and AI crawler rules in robots.txt. Quarterly maintenance, optional.
That's a tractable list. No ongoing content restructuring. No expensive API trackers. No special markup. Just clean technical foundations and non-commodity content.
If you want to run the same audit on your own site, the SEO playbook has the full methodology, updated this week to reflect everything Google told us. And if you'd rather have someone walk through it with you, we do that too.
I used to think AEO was a separate discipline requiring its own tooling and cadence. I built a whole chapter around that assumption. After reading Google's guide and auditing our own site, I think it's a measurement layer on top of existing SEO with one genuinely new technical dimension. The operators who already have strong content fundamentals are most of the way there. The agentic readiness piece is real but bounded, and it's a one-time investment (with a little ongoing discipline around semantic HTML in new components).