title: "Single-Page Calendar to SEO Engine: Architecture That Scaled" slug: single-page-to-seo-engine seo_keyword: "website architecture" meta_description: "How I rebuilt a single-page calendar into a hub-and-spoke website architecture with 1,000+ indexable pages using Next.js ISR and Supabase." og_description: "From 5 URLs to 1,000+ indexable pages: the website architecture decisions, rendering trade-offs, and production gotchas behind a hub-and-spoke SEO engine." cluster: case-studies author: Victor status: published published_date: 2026-03-26 read_time_minutes: 11 description: "Single-Page Calendar to SEO Engine: Architecture That Scaled" domain: steepworks type: article updated: 2026-03-26
BmoreFamilies.com was a single page. One URL. Every event — hundreds of them — loaded into a scrollable calendar grid on /calendar. Users could filter by type or area. Google could not. I had the richest family events database in the Baltimore region and zero organic search presence.
If you don't run an events directory, the pattern still maps. Swap "events" for product integration pages, location landing pages, job listings, partner directories, or customer case studies. Anywhere you have structured data that people are searching for, this architecture earns its keep. The vertical is incidental.
The original site was a Next.js static build: homepage, calendar, about, newsletter archive, subscribe. Five URLs in the sitemap. All event data fetched client-side from Supabase and rendered into a single calendar grid. Good UX. Invisible to search engines.
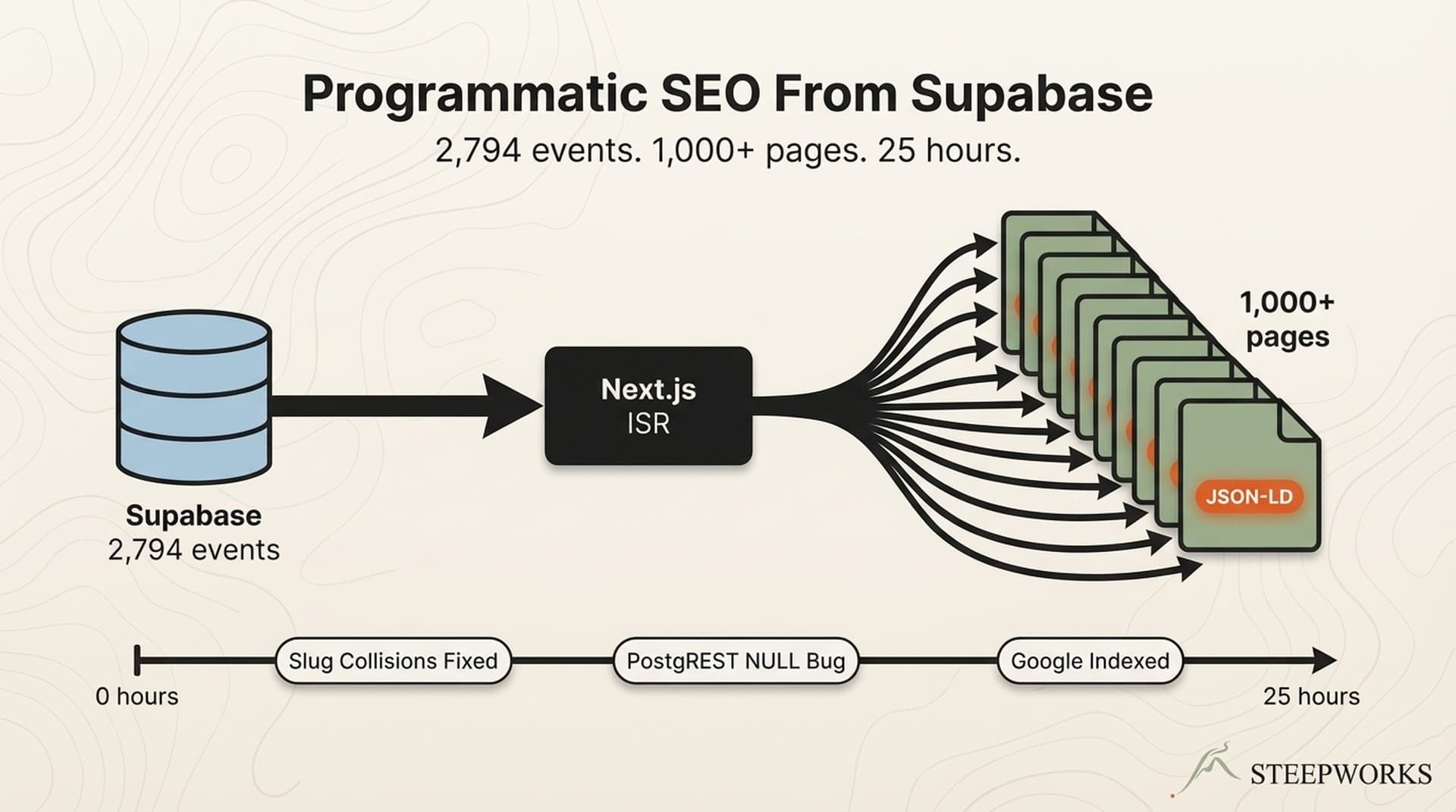
2,794 events in the database. Over 313 sources feeding new events weekly. Rich, unique, locally relevant data — trapped behind a client-side render with no URL structure. Long-tail queries like "free museum days Baltimore" or "toddler activities Howard County" had no corresponding URL. The calendar was a single-page application: JavaScript-rendered, no individual event URLs, no structured data, no crawlable content beyond the page shell.
This is how I rebuilt it into a hub-and-spoke SEO engine with 1,000+ individually indexable pages. The decisions, the tradeoffs, and what happened next.
I've written separately about the programmatic page generation engine. This article covers the architecture layer underneath — why the original structure failed and how the new one was designed.
Diagnosing the Problem
What Google Saw vs. What Users Saw
Users saw a functional calendar with filters. Click an event, see details in a modal. Responsive, fast, good UX.
Google saw five static HTML pages. The calendar had a loading spinner and a <div id="root"> with no content until JavaScript executed. Even with Googlebot's JavaScript rendering, individual events had no distinct URLs — no way to index "Polar Bear Plunge at Sandy Point State Park" as a standalone page.
Good UX and good SEO are not the same problem. A single-page application can have outstanding user experience while being invisible to search engines.
The Crawl Budget Math
With 5 URLs, Google had nothing to crawl. Crawl budget wasn't the constraint — discoverability was.
Google allocates crawl budget based on perceived site importance. A 5-page site with no backlinks gets minimal attention. Even if I added 1,000 event URLs overnight, Google would treat a small domain suddenly claiming that many pages with suspicion.
The migration wasn't just "add more pages." It required a plan for how Google would discover, trust, and progressively index the new architecture.
The New Architecture — Hub-and-Spoke at Scale
A central calendar page links down to category hub pages, which link down to individual event pages. Every page links back up through breadcrumbs. The internal link graph is fully connected.
Three Layers of URL Structure
Layer 1 — The Calendar (entry point). /calendar — the original page, redesigned as an entry point linking to category hubs with highlighted events. Still has filter functionality, now also serves as a navigation hub.
Layer 2 — Category Hubs (medium-tail keywords). 22+ hub pages across four dimensions:
- By type (10 pages):
/events/type/museum,/events/type/outdoor,/events/type/stem - By area (5 pages):
/events/area/baltimore-city,/events/area/howard-county - By age (7 pages):
/events/age/toddler,/events/age/elementary - By intent (2 pages):
/events/free,/events/this-weekend
Each hub targets a medium-tail keyword: "museums for kids in Baltimore," "free family activities Howard County." Each has hand-written intro copy — not template boilerplate — plus JSON-LD ItemList schema and cross-links to other categories. The taxonomy dimensions aren't arbitrary: they're enforced as database-level CHECK constraints in Supabase. location_area, event_type, age_range_category, and cost_type are all constrained columns. The hubs are projections of the data model, not marketing decisions.
Layer 3 — Event Pages (long-tail keywords). 1,000+ individual event pages at /events/{slug}. Each carries a unique title, description, venue, date, cost, age range, related events section, and JSON-LD Event schema. Slugs are generated from event title plus date: polar-bear-plunge-2026-01-25.
The database layer that makes this possible — Supabase as a headless CMS — is its own story. PostgREST auto-generates REST endpoints from the schema, so the website pulls event data without custom API code. The schema is the API.
The Internal Link Graph
The architecture creates a connected graph, not a flat list:
- Top-down: Homepage -> Calendar -> Category Hubs -> Event Pages
- Bottom-up: Event Pages -> Category Hubs -> Calendar -> Homepage (via breadcrumbs)
- Lateral: Event Pages -> Related Event Pages (via "Related Events" section)
- Cross-channel: Event Pages <-> Newsletter Archive (bidirectional links when events were featured)
Every event detail page renders a four-level breadcrumb: Home > Calendar > [Type Category] > [Event Title]. Each node is a link. Each link passes authority downward through the spoke and upward through the hub.
Google uses internal links to discover pages and distribute authority. A flat architecture where every page links only to the homepage concentrates authority at the top. Hub-and-spoke distributes it to the pages that need it — category hubs targeting competitive medium-tail keywords, and event pages targeting long-tail queries.
Google's sitemap documentation describes sitemap-driven discovery for large sites, but internal links remain the primary mechanism for communicating page importance.
The Rendering Decision That Made It Work
Architecture isn't just URL structure. The rendering strategy determines whether Google gets pre-rendered HTML or a JavaScript shell.
I evaluated three options.
Full Static Site Generation (SSG). Build all 1,000+ pages at deploy time. Fast for Google, slow for deploys. Every new event requires a full rebuild. With events changing weekly and new events arriving daily from 313+ sources, rebuild times grow linearly. Rejected.
Server-Side Rendering (SSR). Render each page on request. Fresh data every time, but slower response times, higher server costs, and a slower page for Google's crawler. For a directory with mostly stable content, rendering on every request is wasteful. Rejected.
Incremental Static Regeneration (ISR). Pre-render as static HTML. Regenerate in the background at a set interval. New pages generated on first request and cached. This was the answer.
Event detail pages set revalidate = 3600 — one hour. Hub pages use revalidate = 1800 because they change more frequently. Google gets static HTML (fast, crawlable), users get fresh-enough data (1 hour max staleness), new events appear without a deploy.
generateStaticParams() queries all event slugs from Supabase and pre-renders them at build time. New events arriving between builds render on first request, then cache. The ISR pattern gives you static performance with dynamic freshness — stale-while-revalidate applied to entire pages.
For readers evaluating this for their own stack: Vercel's ISR documentation covers deployment details. Next.js dynamic routes with generateStaticParams covers the code-side implementation.
What Broke During the Migration
No architecture guide mentions the failures. Here's what happened when a 5-page site became 1,000 pages overnight.
Sitemap shock. 5 URLs to 1,000+ in a single deploy. Google Search Console flagged no errors, but indexing was slow — a new domain suddenly claiming 1,000 pages looks suspicious. Weeks, not days, before Google crawled beyond the homepage and category hubs. Patience was the only fix.
Slug collisions on recurring events. Weekly recurring events with the same title and date generated identical slugs. "Story Time at Enoch Pratt" happens every Saturday — 52 potential collisions per year. Fix: a SQL trigger that detects collisions and appends the database ID. 55 collision groups resolved in one migration.
PostgREST NULL filtering. Supabase's PostgREST API uses neq filters that silently exclude NULL values. Filtering for urgency.neq.expired dropped 63+ future events because their urgency was NULL — unclassified. Fix: explicit NULL handling — or(urgency.neq.expired,urgency.is.null). Invisible until I noticed event counts dropping and traced it through the query chain.
Stale related events after ISR window. The "Related Events" section pulled from the same ISR cache. Cancelled events still appeared as related on other pages until the next regeneration. Acceptable for a 1-hour window on a directory. Unacceptable for a ticketing platform.
Breadcrumb mismatch on edge cases. Events with multiple valid categories — a "free outdoor STEM event for toddlers" — had to pick one primary category for the breadcrumb path. That choice affects which hub gets the link equity. Fix: primary category assigned by the pipeline based on specificity (most specific wins), secondary categories rendered as pill links on the event page. (See also: event scraper agent)
Structured Data as Architecture
Structured data isn't decoration — it's an architecture layer that tells Google what each page means, not just what it contains.
Event JSON-LD on every event page: name, startDate, endDate, location, offers, organizer. This enables rich results — event carousels, date-specific search results, location-based discovery. Generated via a generateEventJsonLd() helper composing schema from 30+ fields. Google's Event structured data docs describe the full spec.
BreadcrumbList JSON-LD on every page: mirrors the visual breadcrumb navigation. Breadcrumb schema and rendered nav are generated from the same data — no divergence possible.
ItemList JSON-LD on category hubs: lists up to 20 events with position, name, and URL. Tells Google the hub aggregates individual pages, not a standalone document.
Organization + WebSite JSON-LD on the homepage: site-level identity, search action for sitelinks search box.
This creates a parallel architecture that search engines parse without rendering. Even if Google's JavaScript renderer fails, the JSON-LD in the <head> communicates what the page is and how it relates to other pages.
Google's helpful content guidelines make the quality bar clear: programmatic pages must provide genuine value. Each event page has unique data across 30+ fields — title, description, venue, date range, cost, age range, location area, event type, accessibility notes, registration links. Not a template with one variable swapped.
The dynamic sitemap strategy for getting these pages indexed is covered in a companion article.
Results
Structural results were measurable immediately. Traffic results compound over months.
Structural:
- Indexable pages: 5 to 1,000+. Every event now has its own URL, metadata, and structured data.
- Sitemap URLs: 5 to 1,000+. Category hubs at
priority: 0.7, active events at0.6, past events at0.3. - Page generation velocity: New events in the sitemap within 1 hour via ISR, zero manual effort. 313+ sources feeding weekly.
- Internal link density: From near-zero to a fully connected graph. Each event links to 6 related events, its parent hub, and the calendar entry point. Each hub links to all child events.
Early traffic indicators (Search Console, first weeks):
- Indexing progression: Google indexed category hubs first (medium-tail keywords, higher authority from internal links), then progressively discovered event pages.
- Query diversity: Long-tail queries appearing in impressions — specific event names, "free [activity] Baltimore" patterns, "[venue] events this weekend" combinations. Before: zero matching URLs.
- Hub pages rank faster:
/events/freeand/events/this-weekendcaptured high-intent searches before individual event pages. Confirmed the hub-and-spoke decision — hubs serve as authority anchors.
Cost:
- Infrastructure: Vercel Pro ($20/month) + Supabase Pro ($25/month). Compare to Contentful at $300+/month or a content writer at $5,000+/month producing 4 posts.
- Build cost: ~14 iterations across 2 focused days. The data already existed — the sprint surfaced it as indexable pages.
For context: comparable migrations show results at the 3-6 month mark. Omnius saw 3,035% organic growth over 10 months with programmatic SEO. Next.js migration case studies report 40-150% organic traffic increases within 3 months.
After the migration, I ran a 13-phase automated SEO audit to verify every architectural decision.
The Sprint — 14 Iterations in 2 Days
~14 iterations across 2 focused days. Not one heroic session — a sequence of build-test-ship cycles:
- Database migration: Add
slugcolumn, create slug generation trigger, backfill 2,794 events - Event detail page:
/events/[slug]/page.tsxwithgenerateStaticParams()andrevalidate = 3600 - Dynamic metadata: Title, description, OG tags from event data
- Event JSON-LD schema on detail pages
- Category hub pages: Type, area, age range facets — each with its own route file
- Hub editorial content: 22 unique intro paragraphs — museums, outdoor adventures, seasonal events, and so on. Not generated. Written.
- BreadcrumbList JSON-LD on detail + hub pages
- Dynamic sitemap: Query all slugs, weight by active/expired status
- Noindex logic: Events older than 6 months get
robots: { index: false, follow: true } - Cross-linking: Event detail to hubs, hubs to events, hub-to-hub navigation
- Related events: 3-card section on each detail page via
fetchRelatedEvents() - Special hub pages:
/events/freeand/events/this-weekend— intent-driven entry points - Expired event handling: Past-event banner with CTA to browse upcoming events
- Sitemap submission and Search Console verification
Caveat: this sprint started with 2,794 events already classified in the database. The data collection and classification pipeline was separate work — weeks of scraper development, AI classification, and moderation. The 2-day sprint covers page generation only.
The key insight: the hardest part was not building pages. It was lifecycle management for content that expires. Events have dates. Dates pass. Without noindex logic and expired-event handling, the site accumulates dead pages that degrade the index. Lifecycle management — not page generation — separates a useful directory from an SEO liability.
When This Pattern Applies (and When It Doesn't)
Hub-and-spoke with database-driven page generation works when:
- You have genuinely unique, search-worthy content (events, listings, products, properties, integrations)
- Each record answers a distinct query people actually type
- You can enrich beyond raw data — related items, structured data, editorial context, cross-links
- Content refreshes naturally (new events, updated listings, seasonal inventory)
Same pattern behind Zapier's integration pages (50,000+ landing pages for every app-to-app combination), Zillow's property listings (millions of pages plus neighborhood hubs), and Yelp's business listings (individual pages plus category and location hubs). Three-layer architecture at different scales.
When it doesn't work:
- Data is thin (one sentence per record won't sustain a page)
- Records are interchangeable (swapping one variable doesn't create a different page)
- You can't maintain quality at the scale you're generating
- Your domain doesn't have enough authority to get Google to crawl 1,000+ new pages
- You cannot maintain the pipeline — dead pages with stale data are worse than no pages
The Quality Bar
Google's helpful content guidelines are clear: programmatic pages must provide genuine value. The test: does each page answer a question a real person would ask? "What's happening at the Maryland Zoo this weekend?" is a real question with a real answer. "Events in City 847" is not.
Higher-Risk Use Cases
Events have inherent uniqueness — every record is a different date, venue, description, and age range. Integration pages, partner directories, and location landing pages need more work. If your integration page is just "Product A + Product B" with a template sentence, Google will devalue the lot. You need real use cases, data flow examples, or customer quotes per page. The pattern works, but content investment scales with how thin your base data is.
Stack-Agnostic Note
This case study uses Next.js and Supabase, but the principles transfer to any stack. WordPress with custom post types and WP REST API, Rails with dynamic routes, or static site generators with build-time data fetching. The decisions (hub-and-spoke URLs, ISR-equivalent rendering, structured data, lifecycle management) matter more than the framework.
The line between "helpful directory" and "low-value pages" is whether each URL is the best answer for a specific query. If your page aggregates data from hundreds of sources into one clean, schema-marked, internally-linked answer — that's the architecture doing its job.
What I Would Do Differently
Start with hub pages before event pages. Hubs establish topical authority faster — broader keywords, higher search volume. Event pages then benefit from the domain authority hubs build. I did it in reverse and the hubs still indexed faster.
Automate slug collision resolution from day one. The backfill script handled existing collisions, but new collisions required manual intervention until I updated the trigger. A few hours upfront would have prevented a week of edge-case debugging.
Build a monitoring dashboard from day one. Flying blind for the first two weeks. Without tracking indexed pages, crawl coverage, and index turnover, I couldn't tell whether the engine was working or stalling.
Write hub page intros first, not last. Hub editorial was an afterthought — iteration 6 of 14. Should have been the first deliverable. Those intros carry the most SEO weight per word in the system.
Track these metrics from the start: Pages indexed (target: 80%+ of submitted URLs within 30 days). Organic impressions by page type. Crawl coverage — are new pages discovered within the ISR window? Index turnover — new pages indexed minus deindexed expired pages per week. Without these, you can't tell whether the engine is compounding or decaying.