title: "3 Brand Newsletters, 1 Data Pipeline: Shared Architecture" slug: 3-brand-newsletters-1-pipeline seo_keyword: "multi-brand content automation" meta_description: "A shared data pipeline powering 3 brand newsletters with multi-brand content automation — shared scrapers, classifiers, and brand generation." og_description: "3 brand newsletters from 1 shared pipeline. The database architecture, shared scrapers, brand-specific generation, and economics of multi-brand content automation." cluster: case-studies author: Victor status: published published_date: 2026-03-26 read_time_minutes: 9 description: "3 Brand Newsletters, 1 Data Pipeline: Shared Architecture" domain: steepworks type: article updated: 2026-03-26
The Second Newsletter Forced the Architecture Question
I launched the first newsletter with a quick-and-dirty scraping setup and a single database. It worked. When I started brand #2, I had a choice: copy the entire stack or figure out how to share infrastructure. Copying would have been faster by a week. Sharing would compound over months. I chose sharing.
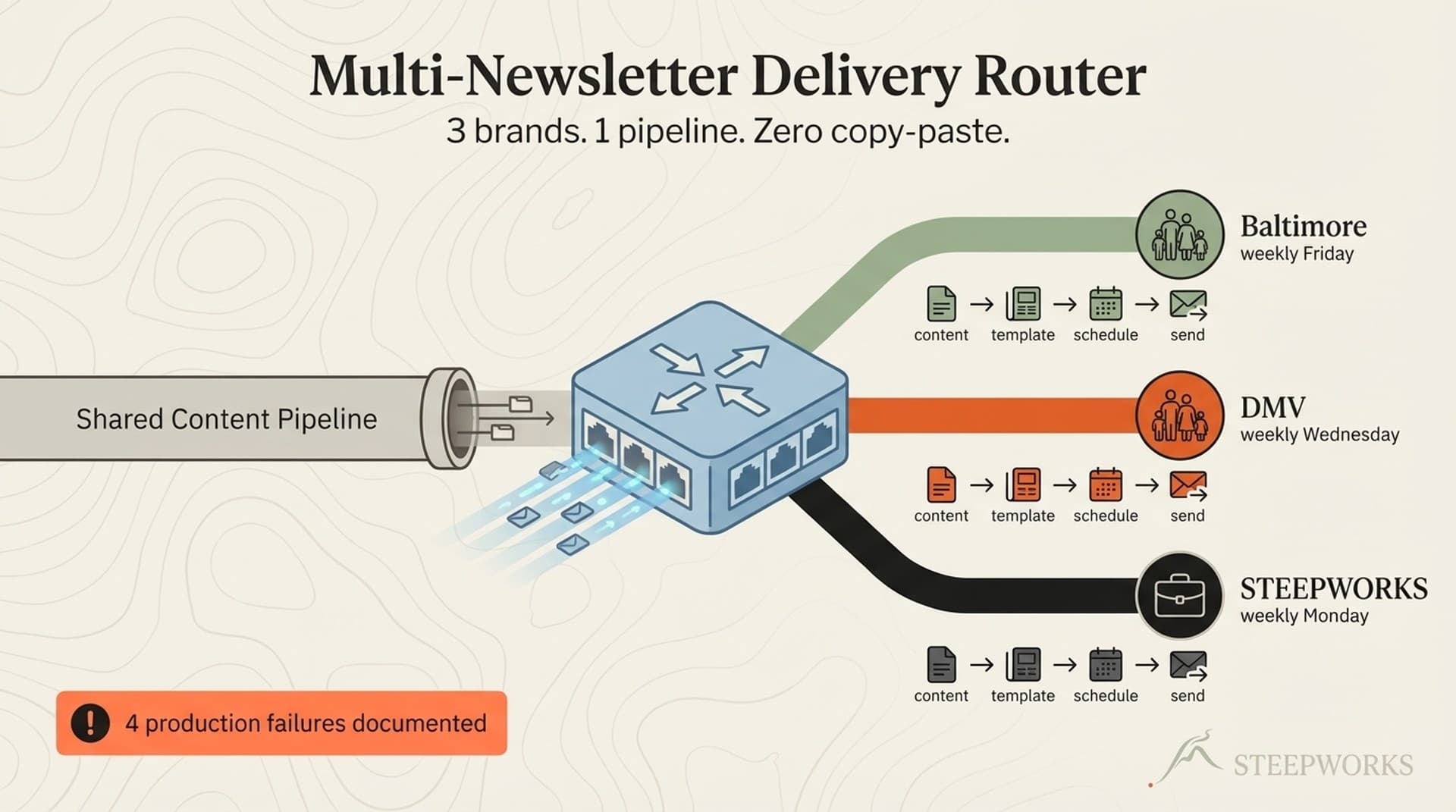
Three brands, related but distinct audiences. A Baltimore family events newsletter. A DC/Maryland/Virginia family events newsletter. A general-audience Baltimore activities newsletter in development. Same mission — curated local events via AI plus human curation. Different geographies, different brand identities, different audience expectations.
Multi-brand content automation sounds like a scaling problem. It's an architecture problem. Scaling asks "how do I produce more content?" Architecture asks "how do I produce different content from the same data without building everything twice?"
This article walks through what I built: shared database, shared scrapers, shared classifiers, brand-specific generation, and the economics of adding a marginal brand. The numbers are from a production system running for months.
One Schema, One Region Column
The first decision was database architecture. Two options: separate schemas per brand (complete isolation, independent evolution) or shared tables with a region discriminator column (one migration path, shared deduplication, cross-brand analytics). I chose shared tables.
Shared tables win for small operations. One ALTER TABLE applies to all brands. With separate schemas, every migration runs twice — or three times, or N times. For a solo operator, migration drift is a matter of when, not if. I've shipped 19 migrations. Running each against three separate schemas, keeping them in sync, debugging drift when they diverge? That's a part-time job I don't have budget for.
Deduplication works across brands. Events near geographic boundaries appear in sources for both regions. Montgomery County sits in the overlap between Baltimore and DC coverage. Shared tables let dedup logic see both, preventing double-counting while preserving both brands' access.
Cross-brand analytics are trivial. SELECT region, COUNT(*) FROM events GROUP BY region — one query, full picture. Separate schemas means a cross-database join or application-level merge.
Adding a brand is a column value, not a new schema. Brand #3 required zero schema changes — one new region value and one new public view.
The three-layer region guardrail. Shared tables create a data integrity risk: what happens when an event gets ingested without a region tag? Three layers of defense. Scraper configuration sets region at ingestion. The AI classifier has a fallback if region is missing. The database enforces NOT NULL with a CHECK constraint. An event without a region cannot exist.
This is the "shared database with tenant discriminator" pattern from multi-tenant architecture. Not novel — proven architecture applied to a content pipeline instead of a SaaS product. The region column is the tenant discriminator. Public views are the tenant-scoped access layer.
Shared Scrapers, Shared Classifiers — Where Marginal Cost Approaches Zero
Scrapers and classifiers are the expensive, fragile parts of any content pipeline. Sharing them is where compounding lives.
Scraper reuse. 12+ scraper modules covering venue calendars, community boards, aggregator sites, program listings. For brand #2, I didn't write new scrapers — I configured existing modules to cover DC/Virginia sources and tagged output with the new region. The framework (scheduling, error handling, retry logic, shared computeUrgency() utility) was already built. Brand #2 inherited all of it.
Tiered scheduling. Not every source needs daily scraping. Daily for high-churn venues, twice-weekly for moderate sources, weekly for aggregators — reducing infrastructure cost 60-70%. That logic doesn't care which brand the source serves. Build once, every brand benefits.
AI classification runs once per event. Event type, age range, cost, family-friendliness score, venue category — classified once. The classifier doesn't know which brand will use the event. Brand identity is a downstream concern. An Easter egg hunt in Montgomery County gets classified the same way whether Baltimore or DC features it.
The deduplication trigger. The same event often appears in multiple sources. A fingerprint function (normalized title + venue + date) catches duplicates.
An Easter egg hunt in Wheaton, Maryland gets picked up by a Baltimore-area source and a DC-area source. Same fingerprint. The dedup trigger fires on the second insert, checks region = NEW.region — if the existing record targets Baltimore and the new insert targets DMV, the trigger allows it. Both brands get the event.
If both inserts target the same region, source-priority logic kicks in — higher-priority source wins, duplicate merged. This was Migration 018. Before it, cross-region fingerprint collisions silently dropped events from one brand because the trigger didn't check region.
The economics of brand #2 and #3. Brand #2's marginal cost: new scraper configurations (pointing existing modules at new sources), a migration adding a region column, and a new public view. No new schema, classification pipeline, or dedup logic. Brand #1's fixed costs became shared infrastructure.
Brand #3: zero schema changes, one new view, one new generation skill. The pipeline was already multi-brand.
Where Brands Diverge — Voice, Curation, and Generation
Everything upstream is shared. The generation layer is where brands become distinct.
Late differentiation. Brand identity doesn't enter until the last stage. Scraping, classification, storage — all brand-agnostic. Voice, templates, and curation only matter at generation time. The later you introduce differentiation, the more infrastructure you share.
Brand-specific generation skills. Each brand has its own AI generation skill covering voice, tone, template structure, and audience assumptions. Baltimore sounds like "your most organized neighbor who knows every event." DC has "capital-city polish with community warmth." Same data, filtered by region views, shaped by different voice profiles. Baltimore runs a 5-persona team debate for consensus. DMV organizes events by decision mode (not venue type) — a structural choice, not just a tone shift.
Same event, different voice. A spring festival at a botanical garden near the Maryland border. Baltimore: "Pack the stroller and head to the garden this Saturday — free admission, face painting, and a petting zoo. Parking fills up by 10am." DC: "Worth the short drive from the District: the garden hosts its annual spring festival Saturday with activities for all ages. Arrive early — this one draws a crowd." Same database record. Same classification. Different editorial voice.
Brand guide as runtime parameter. Guides aren't baked into infrastructure — they're documents the generation skill reads at runtime. Changing voice means editing a markdown file, not rewriting code. The DC guide was rewritten twice in the first month as we found the right register.
Visual identity and distribution. Each brand has distinct colors, imagery, and its own Beehiiv publication. Subscriber lists are entirely separate — own audience, analytics, domain reputation. The pipeline doesn't know about any of this. No cross-brand subscriber sharing — a limitation for audience insights, a feature for brand integrity and deliverability.
Where voice contamination happens. Early in development, the DC skill picked up Baltimore phrasing because event descriptions came from sources covering both regions. "This weekend at the Inner Harbor" in a DC newsletter. Fix: strict view scoping — the generation skill queries the brand-specific view, never the underlying table. Each description gets regenerated per brand, eliminating duplicate content risk.
The Economics — 3 Brands vs. 3 Separate Stacks
Shared infrastructure (fixed regardless of brand count):
- Database: Supabase free tier. Handles all three brands comfortably.
- Scraper hosting: Scheduled scripts on existing infrastructure. (See also: event scraper agent)
- AI classification: API calls per event, not per brand. Classified once. (See also: knowledge os)
- Cloudflare Worker: Free tier.
- Total: single-digit dollars per month.
Per-brand marginal costs:
- Generation skill: AI API calls per newsletter issue (not per event).
- Beehiiv: Per-publication cost.
- Website hosting: Vercel free tier per brand.
- Scraper sources: New configurations per region, using existing modules.
The counterfactual. Three separate stacks — three databases, three scraper frameworks, three classification pipelines, three dedup systems — triples fixed costs, triples maintenance, and every improvement needs manual replication. In practice, the third stack never gets built. Duplication economics kill the second brand before the third is conceived.
Build-time investment. Brand #1 took several weeks — scrapers, classification, schema, Worker, generation skill. Most was core pipeline work required regardless. The shareability investment: region column, three-layer guardrail, region-scoped views, region-aware dedup. About 10-15% of brand #1's build time.
Brand #2 was configuration: new scraper configs, the region migration, a new generation skill. About 20-25% of brand #1's build time. (how we implement)
Brand #3: zero schema changes. Upfront cost is real but modest, amortizing across every subsequent brand.
Time economics. Migrations run once for all brands. Scraper improvements benefit all. Classification refinements benefit all. Only per-brand cost is generation skill and brand guide maintenance. For a solo operator, this is the difference between running 3 brands and running 1.
What Breaks When Brands Share Infrastructure
Shared infrastructure concentrates risk. Here's what broke. (explore pricing)
Geographic overlap dedup (the Montgomery County problem). Events in Montgomery County appear in sources for both regions. Before Migration 018, the fingerprint trigger merged the same event from two scrapers — dropping one region's copy. Fix: AND region = NEW.region in the dedup trigger. One line of SQL. The bug hid for two weeks because events still existed — just not in both views.
The NULL urgency filter. PostgREST's urgency=neq.expired silently excluded NULL values. 63+ future events disappeared because urgency hadn't been computed yet. Fix: explicit NULL handling. Not a multi-brand bug per se, but shared infrastructure means it hit all brands simultaneously. (course vs done-for-you comparison)
Voice contamination. DC's generation skill pulled Baltimore-specific references from shared sources. "This weekend at the Inner Harbor" in a DC newsletter. Fix: strict view scoping — query the brand view, never the base table. (DIY vs professional setup)
The migration gap. Migration 015 added the region column. The dedup trigger wasn't region-aware until Migration 018. For those weeks, DMV events were correctly tagged but the trigger compared fingerprints across all regions. DC and Baltimore copies of the same event collided; one silently dropped. System looked healthy. Data wasn't. (Claude Code alternatives comparison)
The one-line fix was straightforward, but the gap exposed a real risk: migration sequence matters as much as the migrations themselves. Right destination architecture, data lost in transition. (when to implement Claude Code)
Migration coordination. Every schema change hits all brands at once — usually an advantage (one migration, all updated), but a bad migration breaks everything simultaneously. No rollout-by-brand. Mitigation: thorough testing, easier with one schema than N. (what professional setup includes)
The meta-lesson. Concentrated risk, concentrated fixes. One patch heals all brands. For a solo operator, that beats distributed risk with distributed maintenance. (why Claude Code feels too hard)
The Pattern That Transfers
Not everyone runs newsletters. The architecture transfers. (Knowledge OS explained)
The pattern: Shared upstream (collection, classification, storage) + brand-specific downstream (voice, templates, distribution) + late differentiation (delay brand identity as long as possible). (context engineering deep dive)
Non-geographic example. You sell a platform to enterprise and SMB. Content team needs enterprise case studies (long-form, ROI-focused, procurement-friendly), SMB quick-start guides (shorter, self-serve, time-to-value), and partner co-marketing briefs (your data through partner framing). Raw material is the same: product data, customer outcomes, feature capabilities. (how to evaluate a consultant)
The "region column" equivalent: an audience column — enterprise, smb, partner. Same database, same classification, different generation skills with distinct voice guides. Enterprise writes with "security review" language. SMB writes with "try it this afternoon" energy. Shared upstream, divergent downstream.
Other applications:
- Multi-region marketing. Same competitive intelligence pipeline serves US, EMEA, APAC. Collection shared; regional context at delivery.
- Internal vs. external comms. Same company data feeds investor updates, all-hands, press releases. Shared facts, different framing.
- Content repurposing. Same research feeds blog posts, social, email sequences, sales decks. One research investment, multiple outputs.
The design test. Where does differentiation need to happen? At data collection — separate pipelines make sense. At generation or distribution — shared pipeline opportunity. The principle: delay differentiation until the last possible stage.
This pipeline is a case study in the compound systems approach. For the single-brand version, see Newsletter Pipeline: Scraper to Send.
Should You Build a Shared Pipeline?
Not everyone should. Trade-offs don't work in your favor depending on context.
When shared makes sense:
- Brands share a data domain — same content type, different audiences or regions.
- Small team or solo. Maintenance burden is the bottleneck, not processing speed.
- Differentiation is voice, template, audience — not data source.
- You plan more than 2 brands from the same data.
When separate makes sense:
- Fundamentally different data domains. A tech newsletter and food newsletter share nothing.
- Separate engineering teams per brand with different velocities.
- Regulatory data isolation requirements (GDPR per-region, for instance).
- You need to sell or spin off brands independently.
Minimal viable shared pipeline. Start with a shared database and brand-filtered views. Don't share everything on day one. The database is the easiest layer to share and the hardest to separate later. Get that right first. Then scrapers. Then classification. Generation skills last — most brand-specific, least expensive to duplicate.
For multi-tenant storage trade-offs, Microsoft's architectural approaches for multitenant storage is a solid reference. For event processing with per-tenant isolation, see Aampe's multi-tenant event processing pipeline.
The architecture isn't complicated. Shared tables with a discriminator column, region-scoped views, shared scrapers and classifiers, brand-specific generation skills. The hard part is committing to shareability early enough that you don't retrofit later. If you're building brand #1 and thinking about brand #2, add the region column now.