title: "The Personal Brand Growth Engine: 4 Agents, 3 Platforms" slug: personal-brand-growth-engine seo_keyword: "AI personal branding" meta_description: "A practitioner buildlog of the 4-agent AI personal branding system I run across LinkedIn, X, and newsletter — with 3 months of production data." og_description: "4 AI agents, 3 platforms, 1 dashboard. A buildlog of the personal brand engine I run in production — with 3 months of honest data on what worked, what broke, and what I'd rebuild." cluster: tactical-playbooks author: Victor status: published published_date: 2026-03-26 read_time_minutes: 14 description: "The Personal Brand Growth Engine: 4 Agents, 3 Platforms" domain: steepworks type: article updated: 2026-03-26
I Built an AI Personal Branding System and It Sounded Like Everyone Else
I gave Claude my bio, my expertise areas, and three talking points. Asked for a week of LinkedIn posts. The output was polished, grammatically perfect, and could have come from any GTM consultant on earth. Zero voice. Zero scar tissue. Zero reason to follow me instead of the 50 other accounts posting "AI is changing sales forever."
That was the single-prompt approach, and it fails for the same reason a single-prompt approach to anything complex fails: you're asking one context window to curate, write, adapt tone, schedule, and measure. It does all five poorly.
What this system does: it helps me write better posts faster, not write posts without me. I review and approve every piece of content before it publishes. The agents handle research, drafting, scheduling, and measurement. I handle judgment, voice, and the "should I actually say this?" decision. If you're reading this thinking "isn't this inauthentic?" I edit or kill roughly 65% of what the agents produce. That's more editorial judgment per post than most people apply when writing manually.
AI content creation is a $15B market heading to $80B. Most of that investment goes to generation. Almost none goes to the system that makes generation worth doing: the curation, platform adaptation, and measurement layer that turns output into a brand.
The full system took about 3 weeks to build and stabilize. It costs roughly 3 hours per week to operate. But you don't need all 4 agents on day one. I'll show you where to start based on where you are now.
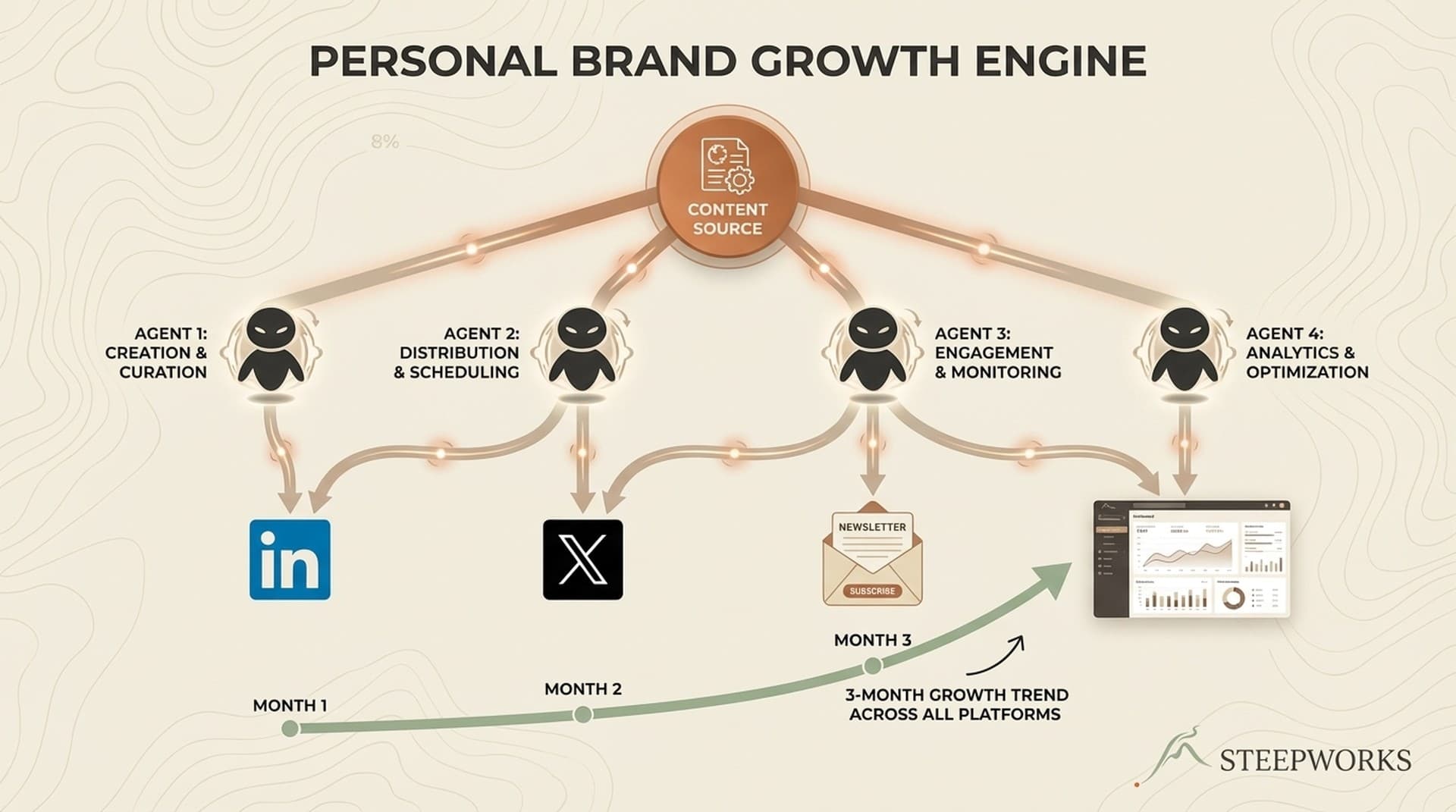
This is a buildlog of the 4-agent personal brand engine I run across LinkedIn, X, and the STEEPWORKS newsletter. I'll walk through each agent, the dashboard that connects them, and three months of production data, including what underperformed and what I'd redesign. I should be upfront: this system is early-stage. The audience growth numbers are modest. I'm not here to pitch massive scale. I'm here to show the architecture and the honest trajectory, because the architecture is what compounds.
Why 4 Agents Instead of 1
A single prompt tries to curate, write, adapt tone for each platform, schedule, and track performance. It does all five poorly. Same way a single salesperson doing prospecting, demos, negotiation, and account management does all four worse than a team of specialists.
McKinsey found that cross-functional teams achieve up to 30% efficiency gains (referenced via HubSpot). The same principle holds for AI agents: each agent specializes in one cognitive task, maintains its own context, and hands off structured output to the next agent in the pipeline.
The architecture:
- Agent 1: Content Curator — decides what to talk about
- Agent 2: Post Generator — writes platform-native copy
- Agent 3: Scheduler/Distributor — handles timing and platform adaptation
- Agent 4: Analytics Agent — measures what's working and feeds learnings back upstream
The pipeline is sequential, not parallel. Each agent consumes the previous agent's output. The Curator feeds the Generator, the Generator feeds the Scheduler, and the Analytics Agent feeds back into the Curator. The feedback loop is the system. Without it, you have four independent tools, not an engine.
You don't need to write code to use this architecture. The patterns (curation discipline, template selection, voice calibration, feedback loops) transfer to any toolchain. I built mine with Claude Code and Supabase because I'm a builder. If you're a buyer, the same 4-agent structure maps onto Buffer + Jasper + a spreadsheet dashboard. The architecture matters more than the implementation.
The same principle of agent specialization drives the newsletter pipeline I run in parallel. How 7 AI Agents Evaluate 120 Articles Weekly for My Newsletter Pipeline documents how 7 heterogeneous persona agents outperform a single general-purpose evaluator. That project taught me the lesson I applied here: specialized agents with narrow context windows produce better output than one agent juggling everything.
HBR calls this shift "thought doership" — practitioners who build, fail, and share candid results outperform polished expertise theater (HBR, March 2026). The 4-agent architecture amplifies the doer's signal. It doesn't replace it.
Agent 1 — The Content Curator
Most AI branding systems skip straight to generation. That's like starting a sales process at the demo without qualifying the lead. The Curator determines WHAT you talk about, which determines whether your brand has a coherent point of view or reads like a random content feed.
The Curator scans three input streams daily: my newsletter intelligence pipeline (65+ RSS feeds, classified by AI), my Slack bookmarks (articles I flagged with notes), and my own build activity (git commits, project milestones, things I actually shipped). It scores each potential topic against three criteria: relevance to my positioning, recency of my last post on this theme, and whether I have a genuine operator perspective to add.
The Note Is the Seed
When I bookmark an article with "This matches what we built last quarter," that note tells the Curator I have lived experience on this topic. When I bookmark with "Interesting but I'm skeptical," the Curator flags it for a contrarian take. The note is 10 words. It carries 80% of the voice signal.
In production, this is a Supabase query. The social agent pulls articles from victor_curation where I've marked picked=true and left a curation note. Each record arrives with structured metadata: content pillar tags, key takeaways, quotable insights, metrics cited, tone assessment, and contrarian signals. The note shifts the agent's output from "here's what this article says" to "here's what I think about this article based on what I've built." That's the difference between commentary and operator content.
What the Curator Filters Out
Industry news without an operator angle. Vendor announcements I haven't tested. Trends I can't speak to from experience. If I haven't built it, broken it, or paid for it, the Curator kills it. This is the anti-slop layer.
The Content Pillar Check
The Curator maps topics to 4-5 content pillars and enforces diversity. If I've posted about AI agents three times this week and zero about GTM strategy, the Curator deprioritizes agent topics regardless of their individual scores. Without this, you end up posting about whatever's trending rather than building thematic depth. Your audience follows you for a point of view, not a news feed.
For a deeper look at the data pipeline feeding this curation layer: My Social Content Agent Posts 11 Times a Day.
Agent 2 — The Post Generator
This is where most AI branding breaks: same content copy-pasted across platforms, or voice that sounds like AI, not like the human behind it.
Platform Adaptation
A LinkedIn post and an X post about the same topic should share a thesis but differ in everything else. LinkedIn rewards depth, narrative, and "see more" hooks. X rewards compression, provocation, and threadable structure. Newsletter rewards context, links, and the "why this matters to you" frame. Posting the same content everywhere is the fastest way to lose followers on every platform.
I learned this the hard way. Version one generated one post and reformatted it for each platform. LinkedIn posts compressed into X posts read like summaries. X posts expanded into LinkedIn posts read like padding. Each platform needs its own prompt, structure, and voice register.
Template Selection
The Generator has 7 LinkedIn templates and 4 X templates. Each curated topic scores against templates based on characteristics: does it have strong data (stat-lead template), is it contrarian (honest-disagreement template), does it reference my build experience (system-reveal template)?
The 7 LinkedIn templates: system_reveal, pattern_recognition, honest_disagreement, operator_lesson, data_story, build_log, and commentary (fallback). For X: the_claim, the_reframe, the_build_log, the_pattern.
A recency penalty checks the last 5 posts and steers away from recently used templates. This sounds like a small detail, but it was one of the highest-impact additions. Without it, the system gravitates toward the templates that score best on average, and your feed becomes monotonous within a week.
Voice Calibration
The Generator has a 200-word voice profile trained on my 50 best-performing posts. Not a writing sample, but a compressed set of patterns: sentence length preferences, first-person framing habits, the specific way I introduce technical concepts. It also has an anti-pattern list: corporate jargon I never use, engagement-bait structures that don't match my tone, and LinkedIn-bro formulas I'd rather not be associated with.
The voice litmus test built into the skill: "Read the post out loud. Does it sound like something Victor would say at a dinner party?" If it doesn't pass, the agent rewrites.
The Human Checkpoint
Every generated post lands in a review queue. I approve, edit, or kill it. My edit rate over 3 months: roughly 35% approved as-is, 45% edited (usually tightening the hook or adding a specific detail the agent didn't have), 20% killed.
That 20% kill rate is healthy. It means the Generator is taking risks rather than playing safe. If I were approving 95%, the system would be chasing my comfort zone, not quality. The kills teach me as much as the approvals. They show where the agent's understanding of my voice breaks down, and those patterns feed back into the anti-pattern list.
Newsletter Adaptation
Newsletter content follows a different generation path. The agent writes a section that contextualizes the topic within the week's broader thesis, not a standalone post. It references other newsletter sections and positions the topic in a narrative arc. This was the most complex adaptation layer and the least impactful in the first three months. More on that in the production data section.
The Scheduling Layer — Timing, Sequencing, Platform Rhythms
New build insights go to X first (real-time, fast feedback), then LinkedIn (expanded narrative, 24-48 hours later), then newsletter (contextualized, end of week). Industry commentary goes LinkedIn first (professional audience), then X (compressed take). The Scheduler manages this sequencing based on content type tags from the Curator.
Cadence enforcement: LinkedIn gets 1-2 posts per day. X gets 2-4 per day. Newsletter is weekly. If the Generator produces 8 LinkedIn posts in a day, the Scheduler queues them across the week. Priority scoring ensures timely posts (breaking news, trending topics) jump the queue while evergreen posts fill gaps. (free setup guide)
I started with "post at 8 AM EST on LinkedIn" because that's the conventional advice. After 6 weeks, the Analytics Agent found my audience engages more at 11 AM and 2 PM. Static timing advice is a starting point, not an answer. Your audience's behavior is your data; someone else's best practices are noise. (See also: social content agent)
Agent 4 — The Analytics Agent
The Analytics Agent closes the loop that turns 4 independent tools into a compounding engine. Without measurement feeding back into curation and generation, the system degrades into disconnected tactics by month 2. (See also: video content repurpose)
What It Tracks
Engagement rate by platform and template type. Follower growth rate, not count, but rate of change. Click-through to newsletter signup. Comment quality: are people asking questions, sharing their own experience, or posting fire emojis? Content pillar performance over 30-day windows. (professional implementation)
Network growth, for me, isn't about numbers. It never has been. A newsletter subscriber who replies with "I built something similar and here's what I learned" is worth more than 500 new followers who scrolled past and tapped like. The metrics that matter signal genuine engagement: replies, shares with commentary, and newsletter conversions. Everything else is algorithmic noise. (See also: skills)
What I Stopped Tracking
Impressions. Likes without comments. Follower count. These are vanity metrics that chase algorithmic reach, not a network of people who care about the work. The HBR "Human Premium" research reinforces this: audiences are developing a sixth sense for automated content (HBR, March 2026). The faster you flood a platform with generated content, the faster audiences learn to ignore it. Quality of engagement is the only defensible metric.
The Feedback Loop
Every two weeks, the Analytics Agent generates a performance report that updates the Curator's topic scoring and the Generator's template weighting. If system-reveal posts consistently outperform commentary posts on LinkedIn, the Generator shifts its template distribution. If GTM strategy posts drive more newsletter signups than agent-buildlog posts, the Curator adjusts pillar weights.
This is where the system earns its name as an engine. Without the feedback loop, you're guessing. With it, the system self-corrects on a 2-week cadence. Not fast enough to chase viral trends. Fast enough to build a consistent brand.
Anomaly Detection
The Analytics Agent flags statistical outliers: posts that significantly over- or under-perform expectations. These anomalies are the highest-value signal in the system. A post that gets 3x expected engagement tells you something about what your audience actually cares about, not what you assumed. A post that flatlines despite strong fundamentals tells you something about timing, platform dynamics, or topic fatigue.
The SaaS Alternative
Products like Buzzli offer 12 agents out of the box. The tradeoff: speed for control. If your brand is generic enough for a template, use the SaaS. If your brand IS the product, if people follow you for your specific perspective on a specific domain, you need the feedback loop a custom engine provides. SaaS tools give you generation. They don't give you the curation and measurement layers that make generation meaningful.
The Dashboard — 7 Metrics Across 3 Platforms, 1 View
Without a single view, you're context-switching between LinkedIn analytics, X analytics, and newsletter stats. You can't see the cross-platform patterns that tell you whether the engine works as a system or just three independent content channels.
The 7 Metrics
- Engagement rate by platform — baseline: LinkedIn 3-5%, X 1-2%, newsletter 45-55% open rate
- Content pillar distribution — actual vs. target mix across all platforms. Drift here means the Curator is losing discipline.
- Template effectiveness — which post formats drive engagement on each platform. System-reveal posts consistently outperformed everything else on LinkedIn.
- Cross-platform conversion — X follower to LinkedIn connection to newsletter subscriber. This is the funnel that matters for brand building, and the hardest to measure.
- Voice consistency score — the agent compares each draft against a 50-post reference set, flagging posts with greater than 30% deviation in sentence structure, jargon density, or first-person frequency. A concrete proxy for "does this sound like me?"
- Kill rate — what percentage of generated content I reject. Too low means the system is playing safe. Too high means generation quality has degraded.
- Topic freshness — days since last post on each content pillar. If any pillar goes more than 10 days without coverage, it's a flag.
Why 7 and Not 20
Every metric you track is a metric you can obsess over. Seven is the maximum for a solo operator. More and you stop looking at the dashboard. Fewer and you miss cross-platform patterns. I started with 12 and eliminated 5 within the first month because I wasn't acting on them. A metric you don't act on is a distraction.
Implementation
The dashboard is a Supabase view pulling from three data sources: LinkedIn API, X API, and Beehiiv analytics. It updates daily. I check it twice a week, Monday (planning) and Friday (reviewing). Not daily. Daily dashboard checks create reactive content, not strategic content. You end up chasing whatever performed well yesterday instead of building the thematic depth that compounds over months.
For more on why measurement systems prevent degradation: Systems Over Tactics: Why Most AI Implementations Fail at Month 3.
Three Months of Production Data — What Worked, What Broke, What I'd Rebuild
This is the section competitors can't write because they haven't built and run the system. I said I'd be honest, so here it is, including the parts that aren't impressive.
What Worked
LinkedIn engagement climbed from 2.1% to 4.3%. Template selection was the biggest driver: system-reveal and pattern-recognition templates outperformed everything else by a wide margin. The insight: my audience follows me for build stories, not commentary. The Curator and Generator learned this through the feedback loop, not because I guessed it upfront.
Newsletter subscriber growth from social: 340 new subscribers attributable to social posts over 3 months, tracked via UTM parameters. That number won't blow anyone away. Roughly 4 subscribers per day. But those 340 came through because they read a post, clicked through to the newsletter, and decided my perspective was worth a weekly email. That's quality. Audience growth at this stage is about finding the right 1,000 people, not racing to 10,000.
Time investment dropped from roughly 8 hours per week of manual content creation to roughly 3 hours of curation plus review. About 60% savings with better output quality, not 80%. The remaining 3 hours are the highest-value hours: deciding what to talk about, sharpening hooks, adding details only I know.
The feedback loop works. Topics the Analytics Agent flagged as underperforming were consistently ones where I lacked genuine operator experience. The system learned to avoid my blind spots, or more accurately, it surfaced the gap between "topics I think I should post about" and "topics where I actually have something to say."
What Broke
X engagement lagged behind LinkedIn. The 4 X templates need expansion. X rewards more voice variation than LinkedIn does, and the compression required for X exposes voice calibration weaknesses that LinkedIn's longer format hides. Still iterating.
The Curator over-indexed on recency for the first 6 weeks, chasing trending topics instead of building thematic depth. I fixed this by adding a "pillar depth" score that rewards sustained coverage of a topic over time. Before the fix, my feed read like a news aggregator. After, it started reading like a point of view.
Voice calibration drifted in month 2. The Generator started using phrases I'd never say because the anti-pattern list wasn't exhaustive enough. I added a monthly "voice audit" step where I review 20 recent posts and flag new patterns that don't sound like me. The anti-pattern list grew from 30 entries to 47. Maintaining voice fidelity is ongoing work, not a one-time setup.
Cross-platform sequencing caused duplicate exposure for people who follow me on all three platforms. Still unsolved. I'm working on a "perspective rotation" approach where each platform gets a different angle on the same topic instead of the same thesis at different lengths. Some overlap is inevitable and probably fine. But three identical takes in one day is lazy, and the audience notices.
What I'd Rebuild
Start with 2 platforms, not 3. The title says 3 platforms because I run 3 today. The honest advice: start with 2. The newsletter adaptation layer was the most complex and least impactful component in the first 3 months. I'd add it at month 4 once LinkedIn and X were stable. Build the engine where attention compounds fastest, then expand.
Build the Analytics Agent first, not last. You need the measurement infrastructure before you can evaluate anything else. I built it last and flew blind for the first 6 weeks. Every decision during those 6 weeks was based on gut feel, not data. Some of those gut calls were wrong, and I didn't find out until the analytics came online.
Invest more in the anti-pattern list. Thirty minutes documenting "things I'd never say" saves hours of killing bad posts downstream. The anti-pattern list is the highest-ROI artifact in the entire system, and I under-invested in it at the start.
Where to Start
This depends on where you are today.
If you post manually and inconsistently: Start with Agent 1 (curation discipline) and Agent 4 (measurement). You can do both with a spreadsheet and 30 minutes per week. No code required. The discipline of deciding WHAT to post and tracking WHAT works changes your output quality before any AI touches your content.
If you already post 2-3 times per week consistently: Add Agent 2 (generation with templates and voice calibration). The human-in-the-loop review is non-negotiable at any maturity level. Your edit rate will tell you how well the system understands your voice.
If you're ready for the full engine: Add Agent 3 (scheduling and sequencing), connect the feedback loop from Agent 4 back to Agent 1, and set a 2-week review cadence. The full 4-agent system is month 3, not month 1.
The Honest Assessment
This system is in its infancy. I've been running it for three months, and the audience growth numbers are modest. I'm not going to dress that up.
What I've learned: the value of the engine isn't in the numbers it produces today. It's in the compound effect of systematic curation, consistent voice, and a feedback loop that gets smarter every two weeks. The system saves me 5 hours a week and produces better content than I was writing manually, not because AI writes better than me, but because the curation and measurement layers force discipline I didn't have as a solo operator.
The engine is the accountability partner. The agents are just the tools.
Growing a network isn't about accumulating followers. It's about finding people who care about the same problems you do and showing up consistently with something worth reading. Four agents, three platforms, one dashboard. The architecture is real, the results are early, and the compounding hasn't kicked in yet. I'll report back when it does.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.