title: "LinkedIn Is Getting Worse. I Use AI Without Slop." slug: linkedin-18m-post-study seo_keyword: "social media algorithms" meta_description: "Social media algorithms decoded: how to encode LinkedIn's 18M-post study into AI content prompts. Data-driven production without the enshittification." og_description: "54% of LinkedIn posts are AI-generated. The algorithm penalizes detectable patterns by 47%. I encoded the 18M-post study into my generation system to fight the slop. Here is how." cluster: tactical-playbooks author: Victor status: published published_date: 2026-03-26 read_time_minutes: 11 description: "LinkedIn Is Getting Worse. I Use AI Without Slop." domain: steepworks type: article updated: 2026-03-26
The Data Changed How I Generate Content (Not What I Post About)
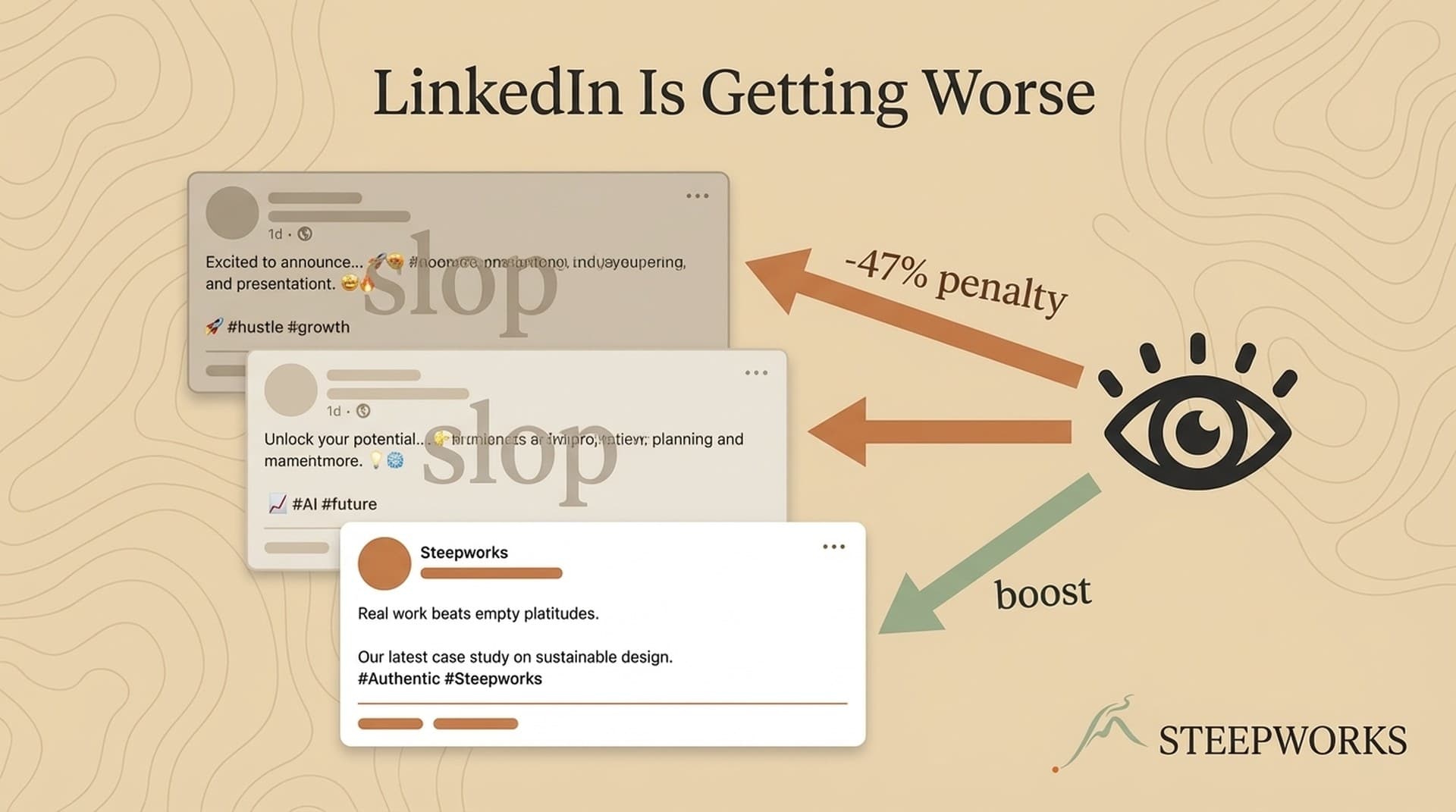
LinkedIn is dying the way all platforms die: slowly, then all at once. The feeds are full of AI-generated platitudes. Every other post follows the same three-line hook, line break, "here's the thing" formula. 54% of long-form LinkedIn posts are likely AI-generated, a 189% surge since ChatGPT launched. The algorithm responds how you'd expect: penalizing patterns it can detect, rewarding content that still feels human.
This is enshittification in real time. Users flood the platform with low-effort AI content. The algorithm downgrades it. Reach declines for everyone. Creators doing real work get punished alongside the ones who weren't.
I was part of the problem for about three months.
I generated LinkedIn posts the way most teams do: prompt that says "create a LinkedIn post about X," review the output, publish. The posts were fine. Grammatically correct, structurally sound, topically relevant. Engagement was flat. When I read them back a week later, I couldn't tell which ones were mine and which could have been written by any operator in my space. That's when I knew the system was broken.
Then I read the research. The "18M posts" in the title comes from multiple editions of the Algorithm Insights Report by Richard van der Blom and Just Connecting, the most cited independent LinkedIn research. The 2024 edition analyzed 1.5M posts from 34,000+ profiles. The 2025 edition covered 1.8M+ posts across 50+ countries. Combined with earlier editions, the body of research spans roughly 18 million posts. The findings compound across editions: 2025 validates and extends 2024, which validated 2023.
The findings didn't change my topics or my voice. They changed how I instruct AI to produce content: format selection, structural patterns, length targets, engagement architecture. They gave me a framework for using AI that fights the enshittification problem instead of feeding it.
This isn't "what to post." This is how to encode what works into the system that produces your posts, while keeping your content from becoming another drop in the AI slop ocean. Whether you're a solo operator or a team with a content lead and social media manager, the principle holds: algorithm research is a system input, not a tip sheet. And anti-slop constraints aren't optional.
What the Research Found
Five numbers that changed how I build content generation systems:
- 47% — organic reach penalty for posts with recognizable AI patterns
- 6.60% — carousel/document engagement rate (highest of any format)
- 15x — algorithmic weight of comments vs. likes
- 13x — engagement rate difference between 3-second and 60+ second dwell time
- 700-900 — optimal character count for image post captions
Each is a design constraint for a content production system.
The AI Content Paradox
Posts with recognizable AI patterns get 47% less organic reach. LinkedIn's AI detection has reached 97% accuracy for engagement pods, and pattern detection keeps improving. Meanwhile, AI-generated posts with personal anecdotes and specific details perform 3-4x better than generic AI outputs.
The implication is not "stop using AI." Most teams use AI in exactly the way that triggers the penalty. Generic prompts produce generic content. Generic content matches the patterns the algorithm flags. The answer: encode the specificity and authenticity signals the algorithm rewards, not the patterns it penalizes.
The Format Hierarchy
Not all formats perform equally, and the gap is wider than most people realize:
- Document/carousel posts: 6.60% engagement rate. Roughly 1,387 average impressions vs. 589 for text-only, a 2.4x multiplier
- Polls regained the top reach multiplier at 1.64x
- Text-only posts: usage down 41% year over year, engagement down 18%
- Image posts: most stable format, 58% of all content. Optimal caption length: 700-900 characters
- Creators using 4+ formats saw 1.4x higher reach loss — pick 2-3 and commit
That last point is counterintuitive. You'd think format diversity would help. The algorithm rewards accounts that develop consistent patterns around fewer formats.
The Dwell Time Signal
Dwell time is now LinkedIn's primary ranking signal. 1.2% engagement at 0-3 seconds vs. 15.6% at 61+ seconds — a 13x difference. LinkedIn now tracks "consumption rate," meaning content completion matters more than initial engagement.
Content delivering real expertise with specific data points gets 3.7x more reach than generalized content. The algorithm actively penalizes the vague, fluffy content that bad AI use produces.
The Engagement Weighting
Comments carry 15x more value than likes for algorithmic ranking. In the first 60 minutes, comments have 2x the weight of likes for initial classification. Author responses within 30 minutes produce 64% more total comments and 2.3x more views. Engagement from relevant industry experts carries roughly 5x more algorithmic weight (likely based on LinkedIn's industry tags and connection overlap; treat directionally).
Practical takeaway: 12 substantive comments outperform 50 generic reactions. The content that generates real comments is content where someone said something specific enough to respond to.
Every one of these findings is a rule to encode, not a tip to remember.
From Findings to Prompt Architecture
This is where the article diverges from every "LinkedIn algorithm tips" post. Those articles tell you what the data says and hope you remember it next time you write. I encoded the findings directly into the system that generates my content.
The principle: every research finding becomes a constraint in the generation prompt. Not a suggestion. A structural requirement.
- Finding: "Document posts get 6.60% engagement" → Rule: Default to carousel/document unless time-sensitive or conversational
- Finding: "Dwell time is the #1 ranking factor" → Rule: Progressive reveals. Each section creates a reason to keep reading. No front-loaded conclusions
- Finding: "Comments are 15x more valuable than likes" → Rule: End every post with a specific, answerable question tied to the reader's experience. Not "What do you think?"
- Finding: "AI-pattern content gets 47% less reach" → Rule: Inject first-person specifics: named tools, specific numbers, real failures. At least one detail that could only come from personal experience
- Finding: "700-900 character optimal caption length" → Rule: Target 700-850 characters for image posts
Four lines of prompt encoding in practice:
Structure: Use progressive disclosure. Open with a specific claim or observation.
Each paragraph must introduce new information that rewards continued reading.
Do NOT front-load the conclusion or summarize the insight in the first sentence.
Close with a specific, answerable question tied to the reader's own experience.
Those four lines encode three findings: dwell time structure (progressive disclosure), comment prompting (specific question close), and the anti-pattern guard (no front-loading). The rest of the prompt handles format, length, and specificity constraints.
A prompt excerpt doesn't convey the full system. The encoding spans format selection logic, voice calibration, template scoring, and anti-slop filters. But the principle stays constant: research finding in, structural constraint out.
Before and After: Progressive Reveal Encoding
Before (front-loaded, typical AI output): "Carousel posts get 6.60% engagement on LinkedIn — the highest of any format. Here's why you should switch your content strategy to prioritize carousels and documents."
After (progressive reveal, encoded constraint): "I shifted 40% of my LinkedIn posts to carousels three months ago. The engagement data from the Algorithm Insights Report said I should. But the data didn't tell me which carousels would work and which would flop — I had to learn that the hard way."
The before version gives away the conclusion in sentence one. Zero reason to keep reading. The after creates a gap between what the data promised and what happened. Same insight, different dwell time outcome.
Watch for optimizing one signal at the expense of others. A post structured for comments but designed for zero dwell time fails. A post built for dwell time with no reason to respond fails. The prompt architecture balances competing signals rather than maximizing one. (free setup guide)
This is the same principle I've written about before: encoding data into process rather than following tips. It's why most AI implementations fail at month 3.
The Authenticity Problem
If you optimize purely for what algorithms reward, you end up with engagement-bait disguised as thought leadership. If you ignore the data entirely, you're writing into a void. Pretending this tension doesn't exist is how people contribute to the problem they complain about. (See also: skills)
I've landed on a distinction that helps: (professional implementation)
Structural optimization (format, length, timing, hook placement) is neutral. Choosing a carousel over text-only is choosing a container. Writing to the 700-900 character sweet spot is a design decision, not an authenticity question. (See also: workflows)
Substance optimization (writing what gets clicks instead of what you believe) is where authenticity dies. If the data says "contrarian takes get more comments" and you start manufacturing positions you don't hold, you've crossed the line. Choosing topics based on what's trending rather than what you've experienced is generating slop with extra steps.
The line I've drawn: the data informs how content is structured. It never dictates what I say or what position I take.
In practice: I had a draft where the AI generated a contrarian angle on AI content detection, arguing LinkedIn's penalties are overblown. The data supported the framing; it would have generated more engagement. But I actually agree the penalties are real. I've seen the 47% reach drop in my own data. So I published the consensus position with my own numbers. Fewer comments. True. That's the line.
Don't get me wrong — ignoring the algorithm is false purity. The test I use: if removing all algorithmic optimization leaves the core insight intact, the optimization is structural. If removing it leaves nothing, the content was never real.
The people flooding LinkedIn with AI slop aren't just using AI — they're using it without this distinction. They're letting the algorithm dictate substance, not just structure. Encode authenticity constraints with the same rigor you encode structural ones.
Production Results
Before: generic AI-generated posts, no algorithm-informed constraints. Decent content, flat performance. The kind of posts that could have been written by anyone with Claude and a vague prompt.
After encoding the study findings:
Format shift: 80% text-only became carousels (40%), image+caption (35%), text (25%).
Structural changes: Progressive reveals on everything. Comment-prompting closes with specific questions. Specificity rules forcing real details into every post.
Length targeting: Image captions hitting 700-900 characters consistently instead of random lengths.
What improved:
- Comment-to-like ratio: From roughly 1:12 to approximately 1:6. Not viral-level, but a structural shift toward the signal the algorithm weights most.
- Engagement floor: The worst data-informed post outperformed the median pre-encoding post by 30-40%. Fewer duds.
- Carousel performance: Data-backed carousels averaged 2-3x the engagement of text-only on the same topics, consistent with the study's format hierarchy.
- Dwell time proxy: Estimated 25-35% improvement based on comment placement and response patterns.
What didn't change:
- Total reach still declined. Impressions per post didn't budge. This is the enshittification headwind.
- Viral outliers stayed unpredictable. The top-performing post in any month was never the most algorithmically tuned.
- The best-performing posts always had genuine insight, regardless of formatting.
Honest assessment: the system produces a higher floor, with fewer duds and more consistent performance. It doesn't raise the ceiling. The ceiling is the quality of the underlying insight. The algorithm can amplify good content or suppress bad content, but it can't create substance where none exists.
On transferability: These results are from a single B2B operator's profile: mid-thousands of followers, GTM/tech audience, 3-4x per week. Similar parameters (B2B, sub-10K followers, professional audience) should yield similar magnitude. Larger accounts or consumer audiences will differ. Use the method and measure your own baseline.
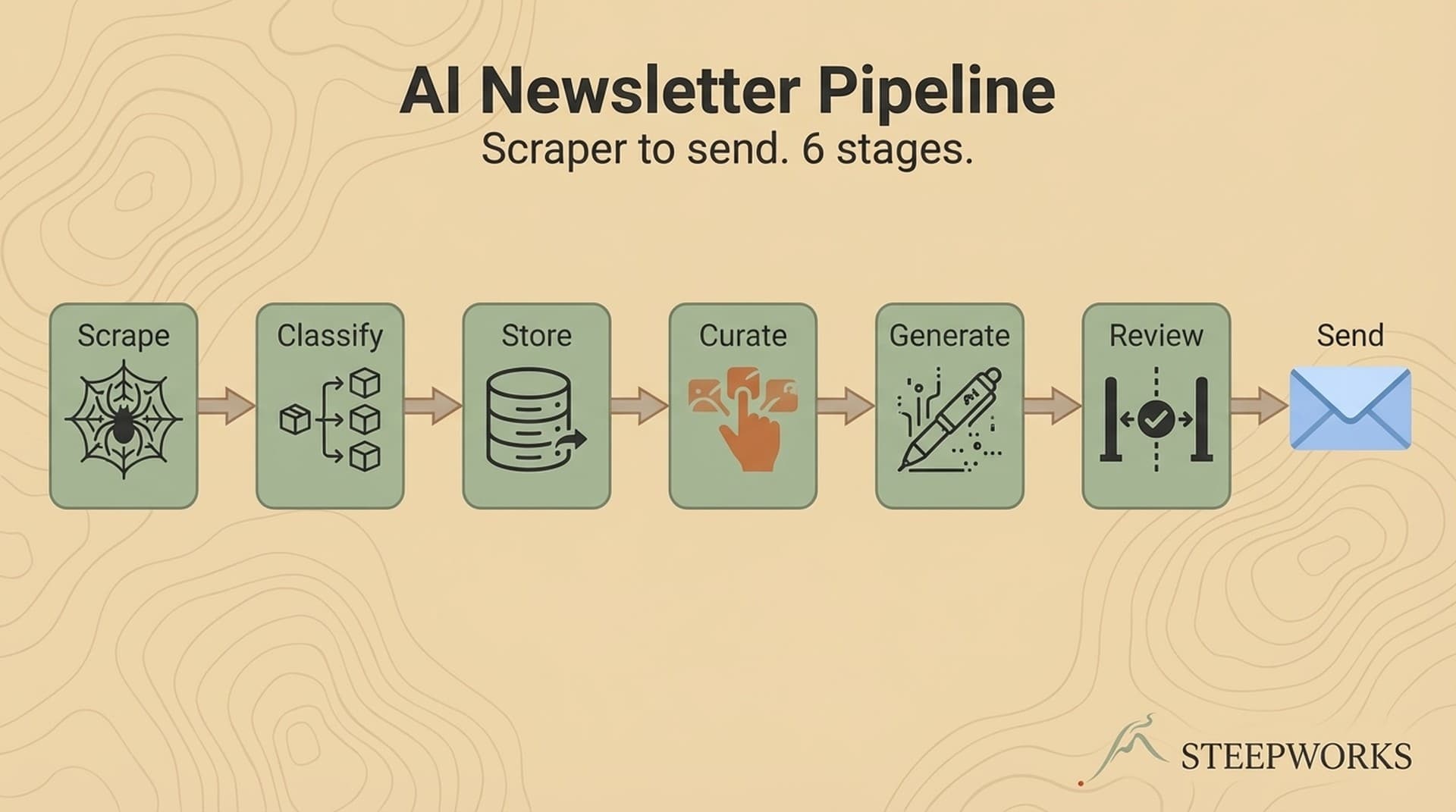
The Generation Workflow
The production sequence and decision points. Not the prompts (proprietary) but enough to build your own system.
Step 1: Content raw material. Every post starts with a real insight, observation, or experience. Not algorithm-first. If there's nothing worth saying, nothing gets generated. First anti-slop guardrail: no "generate something for today" mode.
Step 2: Format selection. The system picks format using a decision matrix:
| Content Type | Format | Why |
|---|---|---|
| Data/research insight | Carousel | 6.60% engagement, progressive reveal fits data storytelling |
| Quick observation | Image + caption (700-900 chars) | Most stable format, optimal dwell time |
| Personal narrative | Text post | Genuine stories with emotional specificity outperform their format's median |
| Industry news commentary | Image + caption | Visual anchor increases dwell time |
| How-to or process breakdown | Carousel | Step-by-step is native to carousel |
Tape this to your monitor. Your social media manager needs a format decision rule, not dwell time theory.
Step 3: Generation with constraints. The AI generates within encoded constraints: target length, structural pattern, specificity requirements, comment-prompting close. A mediocre prompt with strong constraints beats a brilliant prompt with none.
Step 4: Human editorial pass. Non-negotiable. Every post gets a human read for voice fidelity, factual accuracy, and the authenticity test: "Would I say this in a conversation?" If not, it gets rewritten or killed. This is where most operators shortcut, and where AI content becomes detectable. Skip editorial review and you're publishing AI patterns the algorithm penalizes.
Step 5: Scheduling with engagement window. Author response within 30 minutes: 64% more total comments, 2.3x more views. Block that time.
This workflow connects to the broader AI GTM stack, where curation feeds generation, generation feeds distribution, and distribution data feeds back into curation.
What This Doesn't Solve
Most articles in this space oversell. Boundaries worth stating:
It doesn't solve "what to say." The system handles production and formatting. You still need something worth saying. This can't be automated, and it matters most.
It doesn't eliminate variance. Algorithms are stochastic. A well-formatted post with genuine insight can still underperform. A casual text post can go viral. Higher floor, not higher ceiling.
It doesn't replace audience understanding. Format data are averages across millions of posts. Your audience may differ. I've had findings from the study that didn't hold for mine. You will too.
It doesn't make bad content good. Generic insight plus carousel formatting still equals generic content. The biggest engagement lever remains: say something specific, useful, and grounded in experience.
It doesn't account for platform shifts. LinkedIn's algorithm is evolving, with creators reporting significant reach declines. The structural principles (dwell time, comments, AI pattern penalties) are likely durable. Specific numbers will shift. Re-calibrate quarterly.
It doesn't fix enshittification. One operator using AI well doesn't reverse a platform trend. But your content stands out more as average quality drops.
Three Shifts to Make This Week
You don't need the full system to start:
Shift 1: Encode one finding into your generation prompt. Pick the highest-impact finding for your content type. Carousels: encode progressive reveals, no front-loaded conclusions. Image+caption: encode the 700-900 character target and comment-prompting close. One encoded constraint beats ten tips you're trying to remember.
Shift 2: Add a specificity requirement. One line in every content generation prompt: "Include at least one specific number, named tool, or personal experience that could only come from the author." Highest-impact change for avoiding the AI penalty. If the AI can't find something specific, the post shouldn't exist.
Shift 3: Build a 30-minute response window. Author responses within 30 minutes produce 64% more comments and 2.3x more views. Block 30 minutes after every scheduled post. Set a notification trigger. Process change, not willpower change.
The study data is public. The algorithms are documented. The gap isn't information — it's encoding. Operators who treat algorithm research as system inputs will compound their advantage over those who read the same data and change nothing. And the ones who encode authenticity constraints alongside structural ones will be the ones whose content still works when the platform finishes enshittifying everything else.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.