title: "Synthetic Demo Data: Build a Realistic AI Product Demo" slug: synthetic-demo-data seo_keyword: "AI product demo" meta_description: "How I built a synthetic dataset for an AI product demo in 3 days — same schema as production, zero client secrets. The generation pipeline." og_description: "I needed demo data that looked real without exposing client secrets. Three days of work produced a synthetic dataset that mirrors the production schema exactly -- and doubles as a test suite." cluster: infrastructure-buildlogs author: Victor status: published published_date: 2026-03-26 read_time_minutes: 13 description: "Synthetic Demo Data: Build a Realistic AI Product Demo" domain: steepworks type: article updated: 2026-03-26
I needed demo data and I didn't have any.
Not because of a confidentiality problem. The problem was simpler and more embarrassing: the Knowledge OS is a product I built on top of my own personal system. My files, my consulting engagements, my deal pipeline. When I sat down to record walkthrough videos, I realized everything in the system was mine. My actual contacts. My real revenue numbers. My consulting clients' names sitting right there in the folder tree.
I couldn't demo with that. Not because it was illegal — it was my own data — but because it wasn't transferable. A prospect watching a video of my personal consulting pipeline wouldn't see their own workflow reflected. They'd see mine. And the whole point of demo content is that the buyer projects themselves into it.
What followed was three days building a synthetic dataset that mirrors the production Knowledge OS schema exactly — same file structure, same YAML frontmatter, same entity relationships — but with an entirely fabricated company, fabricated contacts, fabricated deals, and fabricated content. Three days to build. Thirty minutes to update per product release. The hard part wasn't generating fake data. It was making fake data look real enough that an operator watching a demo sees their own workflow, not a placeholder.
The primary use case: recording walkthrough videos showing the full onboarding journey — how to take a messy pile of company documents, synthesize the knowledge inside them, and organize it into a structure AI agents can actually use. Every video needs realistic source material to demonstrate the transformation. Template placeholders don't cut it when you're showing a knowledge synthesis workflow.
If you sell a product that touches customer data and you demo it to prospects, you're either solving this problem or ignoring it. This is how I stopped ignoring it.
Why Real Data Can't Be Your Demo — Even When It's "Anonymized"
The obvious risk is client confidentiality. NDAs, SOWs, and basic professional ethics say you don't show Client A's data to Client B. Table stakes. Most people get this far in the reasoning and stop.
The less obvious risk is that anonymization is weaker than people think. Change a company name from "Meridian Analytics" to "Company A" and a savvy buyer can still reverse-engineer it from industry, company size, deal stage, and geography. Pattern matching defeats simple redaction. I've been on the receiving end of "anonymized" competitive briefings where it took about 90 seconds to figure out which company was being discussed. If I can do it, your prospects can too.
Then there's the practical risk: real data is messy in ways that derail demos. Edge cases, incomplete records, context-dependent quirks. You end up explaining data anomalies instead of showing product capabilities. "Oh, ignore that — that contact record is from a deal we lost two years ago" is not what you want to say mid-demo.
The scaling risk compounds over time. Every new client engagement adds data you can't show. Your demo gets stale, or you're spending an hour hand-cleaning production data before every call. I watched a colleague do this — 45 minutes of pre-demo scrubbing before every prospect call, and she still missed a client name in a meeting note once.
And the compliance layer. GDPR, SOC 2, and increasingly restrictive customer contracts limit data usage even for internal demonstrations. If you're building toward enterprise sales, the audit trail matters. "We showed prospect data in a demo environment" is not what your compliance team wants to hear during a SOC 2 audit.
The math is straightforward: spend three days building a synthetic dataset once, or spend 30-60 minutes cleaning real data before every demo forever. The break-even point lands around your tenth demo.
The Schema That Mirrors Production — Design Before You Generate
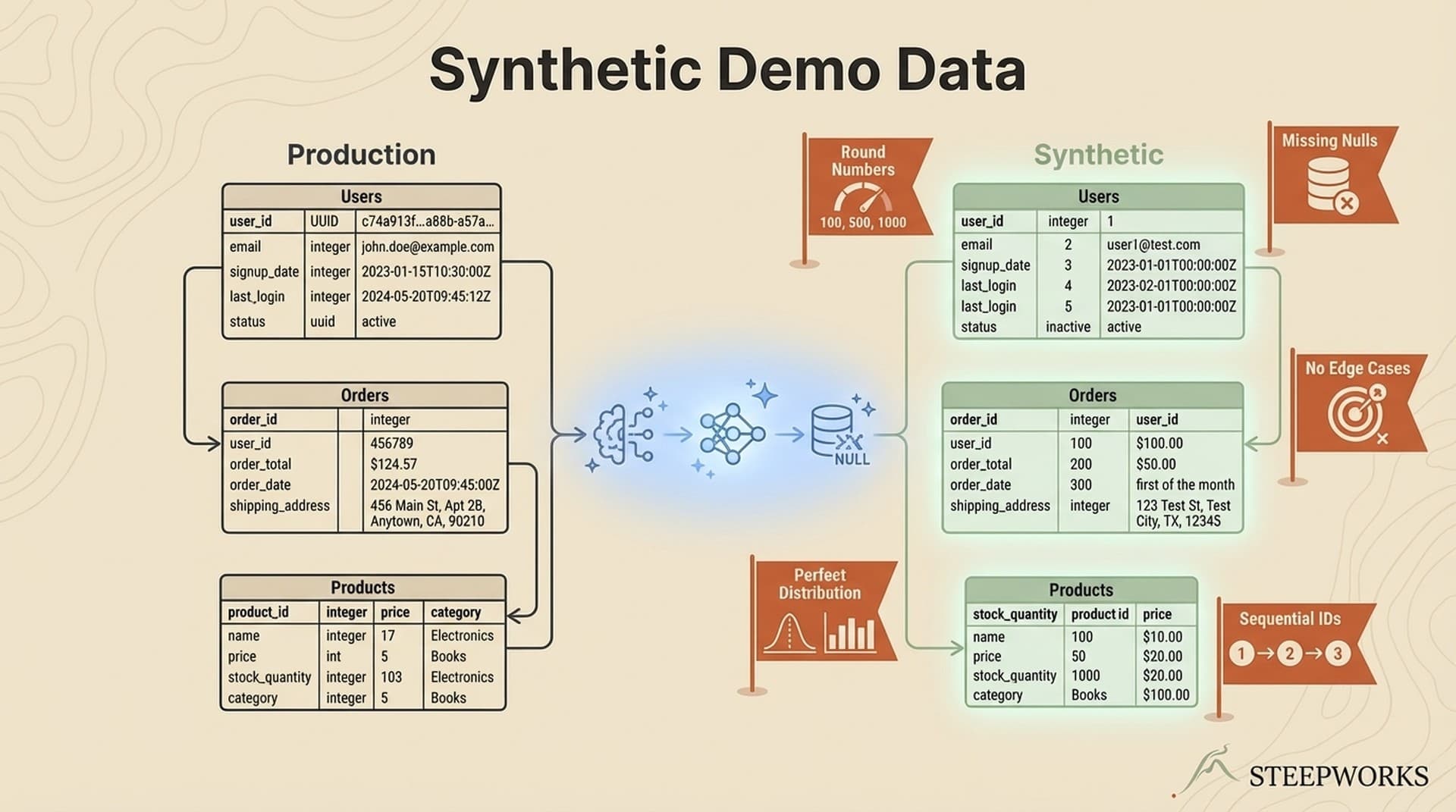
Here's the decision that made everything else work: the demo dataset mirrors the production Knowledge OS structure exactly. Same 16 top-level directories. Same YAML frontmatter fields. Same entity relationships — company flows to contacts, contacts flow to deals, deals flow to content, content flows to skills.
If you looked at the file tree, you couldn't tell which was real and which was synthetic.
The demo schema IS the production schema. No separate "demo mode." No feature flags. No conditional rendering. The system genuinely doesn't know it's running synthetic data. Every skill, every rule, every agent behavior works identically whether the data underneath is real or fabricated.
This is the core architectural insight. Most teams maintain a separate demo environment with its own code paths, its own data model, sometimes its own deployment. That means every product update requires updating two systems. Features ship to production first, the demo environment catches up later (or doesn't), and eventually the demo diverges enough that prospects see capabilities that don't match what they'll actually get. I've seen this kill deals — a prospect falls in love with a feature in the demo that's been deprecated in production for six months.
Schema-as-specification means every entity type has defined fields, valid value ranges, and relationship constraints. A company has a stage field that accepts seed, series-a, series-b, series-c, growth. A contact has a role field constrained to ICP-relevant titles. A deal has a value field whose range scales with company stage. These constraints aren't just documentation — they're the generation rules.
This approach also means the demo dataset is a test dataset. If the Knowledge OS works correctly with synthetic data, it will work correctly with real client data. Every demo I run is a live integration test. When something breaks, I find it before a customer does. That's happened twice so far — once with a skill that couldn't handle a contact without a LinkedIn URL, once with a frontmatter validator that choked on an unrecognized company stage. Both would have been customer-facing bugs without the synthetic dataset catching them first.
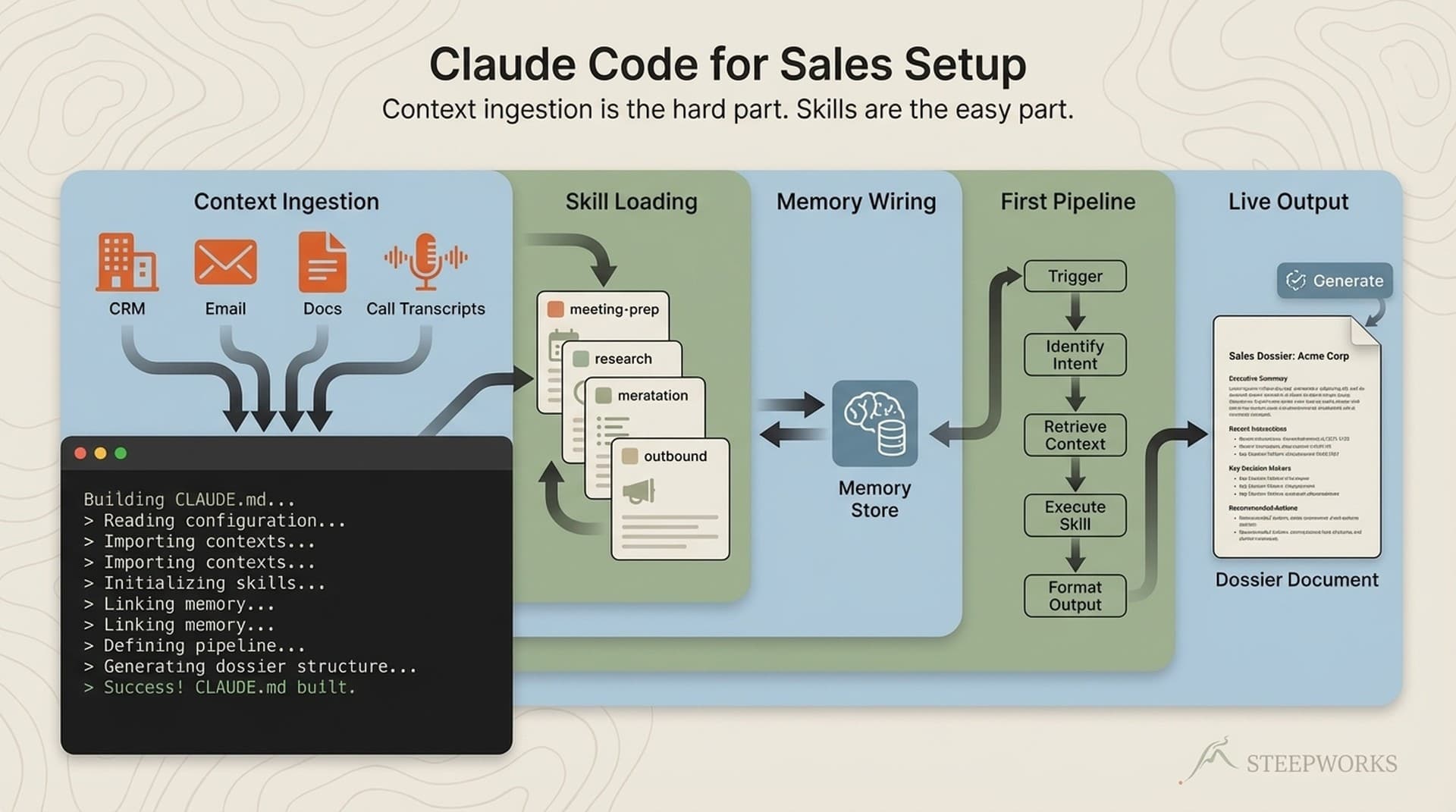
The production system whose schema this mirrors is the same one I described in I Migrated 4,700 Files Into a Knowledge Operating System — 17 numbered domains, 46 skills, 21 behavioral rules loaded by file path.
The Generation Pipeline — From Schema to Believable Dataset
The pipeline has five stages, and the order matters. Each stage constrains the next. Skip ahead and you get data that's internally inconsistent — a company profile that doesn't match its deal sizes, contacts with titles that don't fit the org chart, meeting notes referencing people who don't exist in the dataset.
Stage 1: Company profiles first. I generated one primary synthetic company — Meridian Revenue Labs — with internally consistent attributes. Series B ($28M raised), ~95 employees, Austin TX, selling a revenue intelligence platform to mid-market sales teams. Every attribute constrains what comes next: deal sizes, contact titles, tool stack, and pain points all flow from these seed decisions.
Here's the full company card:
Meridian Revenue Labs
- Stage: Series B ($28M)
- Headcount: ~95 employees
- Industry: Revenue Intelligence / SaaS
- HQ: Austin, TX
- Target Market: Mid-market sales organizations (50-200 reps)
- ARR: $17.8M (up from $2.1M at founding, 2021)
- NRR: ~142%
- Customers: 180
- Product: Deal signal platform (Starter $49/user, Pro $89/user, Enterprise custom)
- Competitors: Gong, Clari, Chorus (acquired by ZoomInfo)
- Key Execs: Priya Sharma (CEO), Tom Liu (CTO), Jake Morrison (VP Sales), Aisha Roberts (VP Marketing)
- Tagline: "Revenue signals your team actually acts on"
Every number in that card constrains the rest of the dataset. A 95-person Series B company doesn't have $200M in pipeline. Their VP Sales doesn't report to a Chief Revenue Officer — they probably report to the CEO. Their deal sizes are mid-market, not enterprise. Get the company card wrong and everything downstream smells off.
Stage 2: Contact networks. Meridian gets 4 executives and a handful of supporting characters — account executives, a RevOps manager, a content marketer. Each one has role-appropriate concerns. The VP Sales cares about forecast accuracy and rep productivity. The RevOps Director cares about data hygiene and integration reliability. These aren't random names attached to random titles — they're coherent personas whose concerns map to their org chart position.
Stage 3: Deal and engagement data. Active deals at various pipeline stages, historical win/loss records, engagement metrics. The numbers need to make sense together. With $17.8M ARR and 180 customers, the average ACV is around $99K. Deals in pipeline should cluster around that range. Win rates should be imperfect — 37% here, not 40.0%. A lost deal retro should reference a real competitor.
Stage 4: Content and knowledge artifacts. This is the hardest layer. Meeting notes, call transcripts, research documents, competitive analyses — 36 files total, all referencing the synthetic company and contacts. The content needs to read like it was written by a real operator, not generated by a template. Call transcripts have filler words ("honestly," "I mean," "like"). A half-finished case study has TODO placeholders. Two pitch decks from different quarters have contradictory ARR numbers ($17.8M vs. $14M), because that's what real company data looks like. An NPS survey includes negative feedback about pricing and onboarding. (See also: dev)
Stage 5: Cross-entity validation. Automated checks confirming referential integrity. Every contact belongs to a valid company. Every deal references existing contacts. Every meeting note mentions real entities from the dataset. Customer quotes that appear in a call transcript also appear in the quotes collection file and the case study draft, because in a real company, the same quote gets reused across five different documents. (See also: prd file)
Generation uses AI agents. Validation uses deterministic scripts. Generation is creative; validation is mechanical. Don't mix them. IBM's synthetic data guidance emphasizes this separation, and it matches what I found in practice — the moment you ask the generation agent to also validate its own output, quality drops.
Who owns this work? In most SaaS orgs, demo data falls somewhere between product marketing and product engineering. Someone needs to own it. For me, that's the person who owns the demo script, because the data should serve the narrative, not the other way around. For teams without a dedicated owner, this is a product marketing task with engineering support for schema alignment. If nobody owns the demo data, it drifts until it's embarrassing.
Total generation time: about 3 hours for the initial 36-file dataset. Updates run about 30 minutes per product release.
What Makes Synthetic Data Convincing vs. Obviously Fake
This is where most demo datasets fail. The schema is correct, the entity types are right, the fields are populated — and it still looks fake within 30 seconds. I've sat through enough vendor demos with obviously synthetic data to catalog the specific tells that kill credibility.
Tell 1: Scale mismatch. A 50-person startup with $200M in pipeline. A Series A company with a 12-person executive team. A solo consultant with 500 active deals. When entity attributes don't scale consistently, operators notice instantly. They live in these numbers every day. Your VP Sales prospect will catch a scale mismatch faster than your engineering team will.
Tell 2: Name uncanny valley. "John Smith" is too generic. "Xylara Moonbeam-Hartington" is too creative. Convincing synthetic names sit in the middle — culturally diverse, regionally appropriate, unremarkable. Same for company names: "Apex Solutions" screams fake. "Ridgeline Data" doesn't. "Meridian Revenue Labs" sits in the believable zone because it sounds like something a founder would actually name their company, not something a data generator would produce.
Tell 3: Flat metrics. Real companies have messy numbers. Win rates aren't exactly 40.0%. Revenue doesn't grow at precisely 15% every quarter. Pipeline coverage isn't a clean 3.0x. Adding controlled noise — variance that looks organic — is the difference between "realistic" and "spreadsheet."
Concrete example. The fake-looking version:
Company A — 40.0% win rate, $50,000 ACV, 3.0x pipeline coverage, 15% QoQ growth
The convincing version:
Ridgeline Data — 37.2% win rate, $47,500 ACV with a Q3 dip to $41,200, 2.7x coverage trending up from 2.3x last quarter
Every AI product demo your buyer has seen uses the first pattern. The second earns trust because it looks like data someone actually tracked, not data someone invented.
Tell 4: Missing temporal depth. Real data has history. A contact was added six months ago. A deal moved from Stage 2 to Stage 3 last Tuesday. A meeting note references a conversation from two weeks prior. Synthetic data without timestamps and temporal relationships feels like a snapshot, not a living system. In my dataset, the Q4 2025 pitch deck shows $14M ARR. The Q1 2026 deck shows $17.8M. The board excerpt shows $18.1M. Three different numbers across three time periods, because that's how real company financials actually look when nobody maintains a single source of truth.
Tell 5: Uniform tone in content artifacts. If every meeting note sounds the same, the content was clearly generated in a single pass. Real meeting notes vary. Some are detailed and structured. Some are three bullet points dashed off on a phone. Some use full sentences, some use fragments. The competitor notes in my dataset range from a structured comparison table (Jake's Clari analysis) to an emotional rant ("I HATE when they say 'we already have Gong'" — Sarah's informal notes) to a two-sentence dismissal (Chorus quick thoughts). Vary the style deliberately.
The fix for each tell is the same principle: constrained randomness. Define realistic ranges, then generate within those ranges with controlled variance. Don't randomize everything — that creates chaos. Don't fix everything — that creates canned data. Find the middle.
For readers who want to go deeper on the tooling side, Tonic.ai's guide to synthetic data generation covers platform-level approaches to several of these problems.
Demo Scenarios — Designing Data for the Story You Need to Tell
The dataset isn't random. It's designed backwards from the demo script. What do I need to show in the walkthrough videos? That determines what the synthetic data contains.
Each buyer persona sees a different slice of the same dataset. The solo operator demo centers on one company with deep content, showing how a single practitioner synthesizes 36 messy documents into an organized knowledge system. The GTM team lead demo shows cross-entity relationships — how deal data connects to competitive intelligence connects to content production. The consulting practice demo highlights multi-client engagement tracking.
Design the data backwards from the narrative. Need to show a competitive analysis workflow? Then the dataset needs competitor notes with varying depth — one thorough, one outdated, one dismissive. Need to demonstrate how the system handles knowledge gaps? Then one persona document should be explicitly labeled "needs refresh" and the case study should have TODO placeholders where metrics should be.
This matters for the video walkthroughs I'm building. Each video demonstrates a specific capability — knowledge synthesis, competitive intelligence extraction, sales enablement assembly — and the demo data needs to support that exact flow without detours.
I included deliberate imperfections. One deal is stuck in Stage 2 with no recent activity. One contact has an incomplete profile. The case study draft has three TODO placeholders. A qualification checklist is labeled "based on our 2024 sales process — probably needs updating." These imperfections are the demo. They show how the Knowledge OS handles the messy reality of GTM work, not just the happy path.
Coaching note for anyone running demos with a sales team: frame imperfections as features, not bugs. "Here's what the product does when data is messy" is a selling point. "Sorry, our demo data isn't complete" is a credibility killer.
For teams running 40+ demos per month, tag scenarios by ICP segment and let AEs select the entry point at demo start. The underlying dataset doesn't change — just the entry point. A dropdown, not a rebuild.
The demo dataset doubles as a test suite. If a new feature works against all three persona scenarios with the synthetic data, it will work in production. I used this approach throughout the B2B package extraction process — the same synthetic data that powers demos also validates the delivery workflow.
When to Build vs. When to Buy a Platform
Not every team should build custom synthetic data. The three days I spent were justified by my specific constraints. Your constraints might point somewhere different.
Build your own when: your product has a unique data model that off-the-shelf generators can't replicate. The Knowledge OS has a 16-directory schema with YAML frontmatter, entity relationships across files, and behavioral rules triggered by file path. No platform generates that. Building also makes sense when you're pre-revenue and don't have production data to mirror, or when your demo narrative requires cross-entity coherence that field-level generators can't provide.
Buy a platform when: your product uses standard SaaS data models — CRM, ERP, HRIS. If you need realistic Salesforce data with masked PII, platforms like Tonic, Syntho, or Saleo are purpose-built for that. Buying also makes sense when you have production data that just needs masking or subsetting, or when your team doesn't have the engineering capacity to maintain a custom pipeline.
The hybrid path is worth considering. Use a platform for individual fields — names, addresses, phone numbers, realistic-looking email domains — and custom scripts for the relational layer. Company flows to contact flows to deal flows to content. The platform handles the atoms; you build the molecules. That gets you 80% of the quality at roughly 50% of the effort.
Cost framing: building custom took me about three days of focused work. Maintaining it takes roughly 30 minutes per product update. A platform subscription runs $500-2,000/month depending on scale and feature set. For a pre-revenue product like the Knowledge OS, the build-it-yourself economics are clear. For a team with 50 sales reps running personalized demos daily, the platform pays for itself in the first month.
The anchor-in-truth principle applies here too. Pure synthetic data generated without any reference to real patterns drifts into artificial territory fast. The most convincing synthetic datasets are seeded with real structural patterns, then populated with fabricated specifics. My company card for Meridian Revenue Labs is fabricated. The schema it follows — Series stage, NRR, ACV ranges, competitive dynamics — is drawn from real B2B SaaS patterns I've seen across 15 years of GTM work. The structure is real. The specifics are invented.
The Demo Is the First Deployment
The demo dataset isn't a sales prop. It's the first deployment of the product.
If the Knowledge OS works with 36 synthetic files organized across 8 directories with cross-entity references and deliberate inconsistencies, it will work with a real client's messy Google Drive export. If the synthetic data reveals edge cases — a skill that breaks on missing fields, a validator that chokes on unexpected values — those bugs get caught before a paying customer hits them.
Demo data quality correlates directly with deal velocity. When a prospect sees data that mirrors their world — realistic company sizes, believable deal values, familiar role titles — they stop evaluating the data and start evaluating the product. That shift is where deals accelerate. The moment a buyer thinks "this looks like my company," the conversation moves from "does this work?" to "how do I get started?"
The market is moving toward personalization at scale. Platforms like Walnut, Navattic, and Reprise are building toward buyer-specific demo environments. The synthetic dataset is the foundation that makes personalization possible — you can't personalize what you haven't built. And if your demo data is just masked production data, personalization means re-masking for every segment. With synthetic data, you swap the company card and regenerate. Thirty minutes, not thirty hours.
Three days of work. Zero secrets exposed. A demo that doubles as a test suite. And a dataset that evolves alongside the product it represents.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.