title: "Go-Live Checklist PRD: Multi-Agent Website Launch" slug: go-live-checklist-prd seo_keyword: "website launch checklist" meta_description: "A website launch checklist restructured as a PRD so AI agents can execute phases independently. Entry criteria, verification, and failure lessons." og_description: "Flat launch checklists break under delegation. I rebuilt mine as a PRD with entry criteria, verification checks, and dependency mapping -- then handed it to 3 AI agents." cluster: infrastructure-buildlogs author: Victor status: published published_date: 2026-03-26 read_time_minutes: 11 description: "Go-Live Checklist PRD: Multi-Agent Website Launch" domain: steepworks type: article updated: 2026-03-26
Every website launch checklist I found assumed the person who wrote it would also execute it. That works when you're doing the work yourself. It stops working the moment you hand it to a contractor, a junior team member, or an AI coding agent. I needed a go-live checklist that three AI agents could execute independently, in parallel where possible, without skipping steps or duplicating work. So I rebuilt the format. Not as a checklist. As a PRD.
What follows is how I got there, what broke, and why the format works better than a flat checklist even if you never touch an AI agent.
Why Flat Checklists Break Under Delegation
I've launched maybe a dozen websites over 15 years of B2B SaaS. For most of that time, I used the same approach everyone uses: a checklist in a Google Doc or Notion page. DNS, SSL, analytics, meta tags, redirects, social previews, all in a tidy numbered list.
It always worked. Because I was the one reading it, and I was the one doing the work. The checklist was a memory aid for someone who already knew the context.
The hidden assumption in every checklist is that the executor carries the same mental model as the author. You write "set up analytics" and you know that means Google Tag Manager container ID GTM-XXXXXXX, firing on all pages, with a custom event for pricing page views. The checklist says none of that. It doesn't need to, because you're both the author and the executor.
Hand that checklist to a contractor and they'll ask six questions before finishing item three. Hand it to an AI agent and something worse happens: they won't ask. They'll skip the item, fill in the blanks with a best guess, or do something confidently wrong.
Three failure modes show up every time:
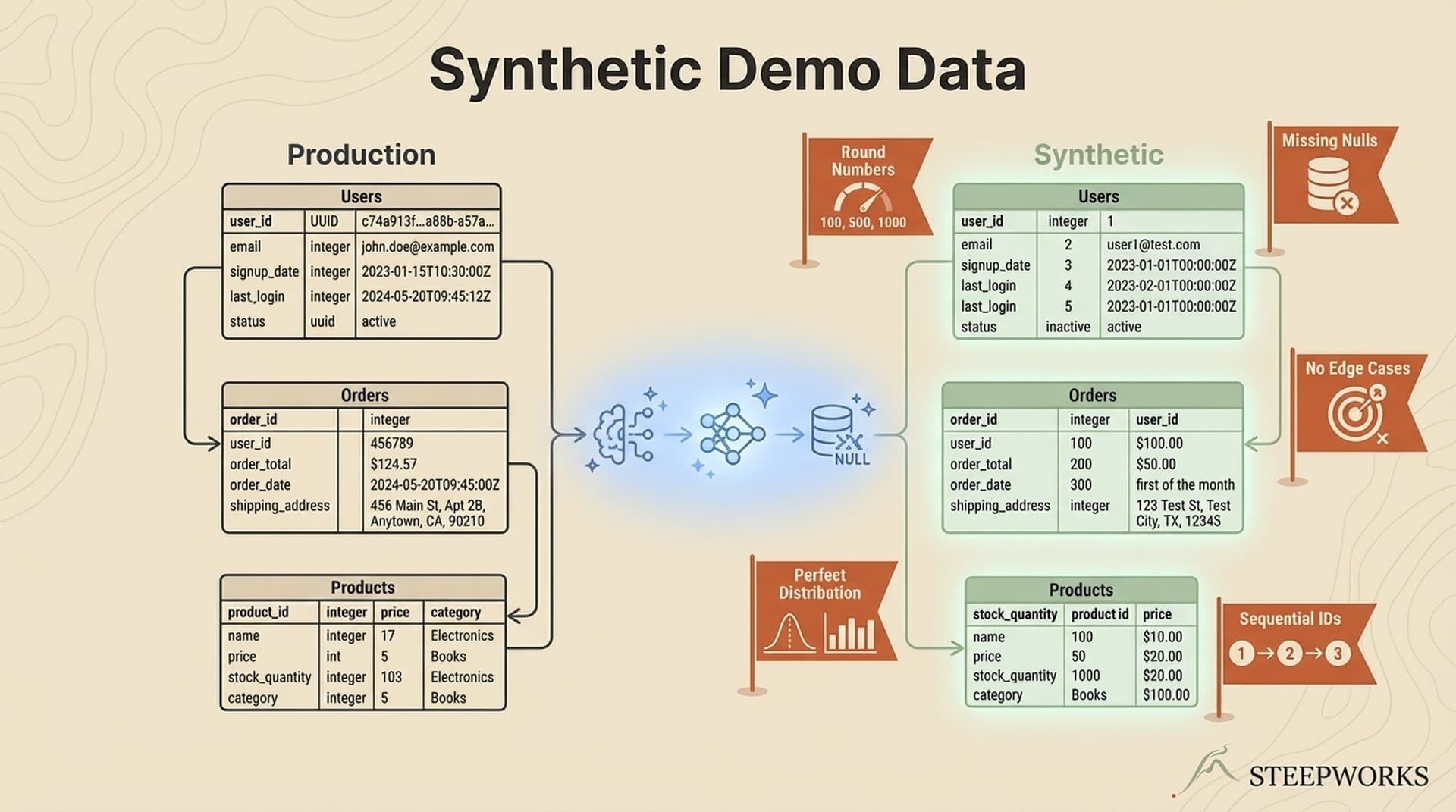
Implicit dependencies. "Update DNS" appears as item 4 and "verify SSL" appears as item 7. The checklist doesn't say that SSL provisioning depends on DNS propagation, or that you should wait 10-30 minutes between them. A human who's done this before knows. A first-timer doesn't. An AI agent definitely doesn't.
Missing verification criteria. "Optimize images" -- to what format? What compression level? What target file size? "Check analytics" -- check that the tag is present in the HTML, or that events are firing in the dashboard? A flat checklist item tells you what to do but not how to know it's done correctly.
Assumed context. "Update the DNS records" -- which records? A records, CNAME, or both? Pointing to what IP? With what TTL? The checklist author knows the answer because they set up the hosting five minutes ago. The executor doesn't, because the checklist never encoded it.
This isn't an AI problem. It's a specification problem. AI agents just surface it faster because they won't stop and ask for clarification -- they'll fill the gap with hallucination or skip the step entirely. As Addy Osmani found in GitHub's analysis of 2,500+ agent config files, the most effective specs encode commands, test expectations, and project structure explicitly. The worst assume the reader already knows.
Quick test: hand your launch checklist to someone with zero context about the project. Can they execute every item without asking a single question? If not, the checklist is incomplete. Nobody noticed because the author was always in the room.
The Format Shift: Checklist to PRD
A PRD -- Product Requirements Document -- is traditionally a planning artifact. I repurposed it as an execution contract: a document detailed enough that any agent (human or AI) can read it cold, execute one phase, update the document, and hand it off.
Five elements distinguish a go-live PRD from a flat checklist:
1. Phases with explicit sequencing. Instead of a flat list of 40 items, group related work into phases that each take 15-60 minutes and produce a verifiable result. "Domain & Hosting" is a phase. "Set up analytics" is an item inside a phase. Phases have boundaries: a clear start, a clear end, and a definition of what "done" looks like.
2. Entry criteria per phase. Before you start Phase 3 (end-to-end purchase test), what must be true? Stripe live keys deployed. Payment endpoint returning 200. Production domain resolving. These aren't nice-to-haves -- they're prerequisites. A flat checklist encodes none of this.
3. Verification criteria per phase. Not "check that it works." Specifically: "https://steepworks.io loads the homepage. SSL padlock shows valid. Staging URL still resolves." Assertions, not vibes. If you can't express the verification as a testable statement, the phase isn't well-defined.
4. Dependency mapping. Which phases block which? In a recent go-live, Phases 1 through 4 were strictly sequential. But Phase 7 (SEO basics) had no dependencies on any of them. Neither did content QA. The dependency map made it obvious which work could run in parallel and which couldn't.
5. State tracking. Each phase carries a status: not_started, in_progress, complete, blocked. Plus who completed it and when. The document tells you where you are without anyone needing to remember.
Here's what surprised me: the PRD for a recent website launch was about 1,800 words. The top five "website launch checklist" posts on page one averaged 3,200 words. The PRD was more structured and shorter. It replaced vague prose with precise criteria.
The mental model shift: a checklist is a reference. A PRD is a contract. Product Compass frames PRDs as planning documents for what to build. What I'm describing is narrower: a PRD that specifies how to execute a build, with enough precision that the executor doesn't need to be in the room.
Why This Isn't a Jira Board
When I described this format to a friend who runs engineering at a Series C company, he said: "That's just Jira with more words."
It's not.
Project management tools -- Asana, Jira, Linear, Monday -- answer one question: is this done? A ticket moves from "To Do" to "In Progress" to "Done." Someone marks it complete. The board updates.
A go-live PRD answers a different question: how do you know it's done?
Take a Jira ticket that says "Set up analytics." Marking it "Done" tells you someone clicked a button. It doesn't tell you whether GTM is firing on all pages, whether the custom pricing-page event is wired, or whether the GA4 property is correctly linked. A human project manager fills this gap with tribal knowledge, Slack threads, and meetings. An AI agent fills it with invention.
In Jira, "done" means someone said it's done. In a go-live PRD, "done" means the verification criteria passed. "Site loads over HTTPS without browser warning" is a verification. "SSL ticket marked complete" is a status update. Not the same thing.
Sequencing has the same gap. Jira has "blocked by" relationships, but they're binary flags. They don't encode what state constitutes "unblocked." "Blocked by DNS setup" doesn't tell you what DNS state you're waiting for, just that another ticket hasn't been marked done yet.
Put differently: project management tools track work. A go-live PRD specifies work. The specification was always the missing piece in my launches, and it's what makes delegation to humans or agents actually work.
Inside the PRD: Anatomy of One Phase
Here's a single phase from a real go-live PRD, lightly redacted. On a flat checklist, this would be one line: "set up analytics."
### Phase 10: Analytics Setup
Owner: Agent + Victor
Blocked by: Phase 1 (production domain resolving)
Actions:
1. Create GA4 property for production domain
2. Create GTM container, install via Next.js <Script> tag
3. Configure page_view tracking (automatic in GA4)
4. Add custom event: pricing_page_view (fires on /pricing load) (See also: [ralph executor](/agents/ralph-executor))
5. Add custom event: checkout_initiated (fires on Stripe redirect) (See also: [knowledge os](/knowledge-os-guide#knowledge-os))
6. Verify real-time reports show test traffic
Verification criteria:
- [ ] GTM container loads on all pages (check via browser DevTools > Network) (See also: [dev](/skills/dev))
- [ ] GA4 real-time report shows page views within 30 seconds of navigation
- [ ] Custom event pricing_page_view fires when /pricing loads
- [ ] Custom event checkout_initiated fires when purchase CTA clicked
- [ ] No console errors related to analytics scripts
Exit state: Analytics fully operational, all events verified in real-time reports
Next phase: Phase 11 (Pre-Launch QA)
The entry criteria ("blocked by Phase 1") mean no agent or team member starts this until the production domain resolves. The verification criteria aren't "check analytics is working" -- they're five testable assertions you can confirm in under two minutes. The exit state tells the next person (or agent) what the world looks like when this phase is done.
This is what Augment Code calls "typed tasks" -- specifications that carry enough type information (inputs, outputs, constraints) for an executor to run them without ambient context. They built this into their agent framework. I built it into a markdown file. Same principle.
One thing worth flagging: this is not a template. I've seen people turn examples like this into generic templates with placeholder text. That defeats the purpose. "GTM container loads on all pages" is useful because it names the exact technology and scope. "[verify tool] works on [pages]" encodes zero context. Every PRD phase should be written for its specific launch with its specific stack.
The Multi-Agent Handoff: 3 Agents, 1 Document
My operating environment during the last go-live was three AI coding agents, each in a separate terminal, sharing a single git repository. Different models, different context windows. The PRD sat in the repo as a markdown file. Each agent's workflow:
- Read the PRD. Parse the current state.
- Find a phase where all entry criteria are met and status is
not_started. - Execute the phase.
- Run the verification criteria.
- Update the phase status to
complete, record the timestamp. - Commit the updated PRD to git.
No agent needed memory of what another agent did. No coordination channel. No standup. The document was the single source of truth -- what I've written about before as systems over tactics. The PRD isn't a tactic applied to a launch. It's a system that makes the launch self-coordinating.
The parallel execution payoff was immediate. Content QA, image optimization, SEO basics, and meta tag verification all ran in parallel -- none depended on each other. DNS, SSL, Stripe configuration, and purchase testing ran sequentially. Three agents working in parallel finished eight phases in the time one would have taken to finish four.
This isn't an AI-only pattern. Replace "three AI agents" with "three contractors" and the structure works identically. The PRD removes coordination overhead by making context explicit. No one asks "is DNS done?" -- they read the document. No one asks "what does done mean?" -- the verification criteria tell them. Research on task decomposition from Microsoft's AutoGen team confirms the principle: LLMs reason better over smaller, well-defined sub-problems than over monolithic multi-step scenarios. Same for humans.
The multi-agent stress test forced every piece of implicit knowledge out of my head and into the document. Three agents operating independently made vagueness immediately visible.
Three Things That Broke
This didn't work on the first run. Three failures shaped the current format.
Failure 1: The skipped phase. One agent evaluated Phase 5 (newsletter signup integration) and determined its entry criteria weren't met -- the Beehiiv API key wasn't configured in environment variables. Correct behavior. So it moved on to Phase 7 (SEO basics), which had no formal dependencies.
The problem: Phase 5 had a soft dependency I hadn't written down. The signup form's success state redirected to a URL that Phase 7's sitemap generation would crawl. Without signup integration complete, the crawler hit an error page and generated a broken sitemap. Twenty minutes of debugging that one line in Phase 7's entry criteria would have prevented: "Phase 5 complete or newsletter routes return valid responses."
Every dependency needs to be explicit. Especially the ones that seem obvious. If you're carrying a dependency in your head, it doesn't exist in the PRD, and an agent won't respect it.
Failure 2: The false verification pass. One criterion for Phase 1 was "SSL certificate is valid." An agent hit the production URL, confirmed a certificate was present, and marked it passed. But the certificate chain was misconfigured -- intermediate cert was missing. Chrome loaded fine (it's forgiving about cert chains). Firefox threw warnings. Some curl implementations broke entirely.
The fix: "SSL certificate is valid" became "site loads over HTTPS in a fresh browser session without certificate warnings, and curl -I https://domain.com returns 200 without SSL errors." The original criterion tested for the artifact (certificate exists). The revised criterion tests for the outcome (site works over HTTPS). That distinction -- artifact vs. outcome -- now guides every verification check I write.
Failure 3: The duplicate execution. Two agents read the PRD within seconds of each other. Both identified Phase 7 as ready. Both generated the sitemap. Both committed. Git handled the merge, but one agent's work was wasted.
The fix: a claimed_by field on each phase. The first agent to commit a claim (identifier + timestamp) wins. The second agent sees the claim on its next read and moves on. No lock. No mutex. A convention -- and for three agents on a website launch, conventions are enough. At higher agent counts, you'd want something stronger. For this, a markdown field works.
The meta-lesson: every failure improved the format. You don't get it right by planning harder. You get it right by running it, watching what breaks, and encoding the fix. If you want to set up the agent environment that executes these PRDs, that article walks through the full setup.
Building Your Own Go-Live PRD
You don't need three AI agents for this. You need a launch coming up and a willingness to be more specific than feels necessary.
Start with your existing checklist. Every item is a candidate. Some become full phases. Others become action items within a phase. A phase should represent 15-60 minutes of coherent work that produces a verifiable result. "Set up DNS" is a phase. "Add A record" is an action item inside it.
For each phase, write entry criteria: what must be true before someone can start this? If the answer is "nothing," it can run in parallel with other dependency-free phases. If it depends on another phase, write that down.
Then write verification criteria: how would a stranger confirm this is done correctly? Not how would you confirm it -- you carry context. If the answer requires judgment or institutional knowledge, the criteria aren't specific enough. "Analytics is working" requires judgment. "GA4 real-time report shows page views within 30 seconds of test navigation" does not.
Map dependencies visually if it helps. Draw arrows between phases. Any phase without an incoming arrow can run in parallel. Most go-lives have 3-4 sequential chains and 4-6 parallel phases. That parallelism is free time savings whether you have multiple agents, multiple contractors, or you just want to context-switch between independent work.
Add state tracking: name, status (not_started / in_progress / complete / blocked), completed_by, completion_date, and a notes field. This turns the PRD from a static document into a living record.
Finally, run the delegation test. Hand the PRD to someone who knows nothing about the project. Every question they ask reveals a gap. Fill it. Run the test again.
Research on multi-agent task decomposition, like TDAG's framework, validates this from the AI side. But the principle predates AI by decades. Clear specifications, explicit dependencies, testable verification -- engineering fundamentals. The PRD format forces you to apply them to a domain where most people wing it.
The Shift That Matters
The real shift isn't from checklist to PRD. It's from implicit knowledge to explicit specification. Every go-live failure I've traced to its root was a context gap -- something I knew but didn't write down.
Writing entry criteria and verification criteria exposed gaps I'd been carrying for years. Things I checked by habit, not intention. Things I'd gotten away with because I happened to be the one executing.
Whether you hand the finished document to three AI agents or three interns or one very organized project manager, the principle holds: if the document is detailed enough to execute without questions, the work gets done right the first time. If it isn't, you'll find out -- either from a question, or from a quiet failure at 2 AM.
The best website launch checklist isn't the longest one. It's the one that works when you're not in the room.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.