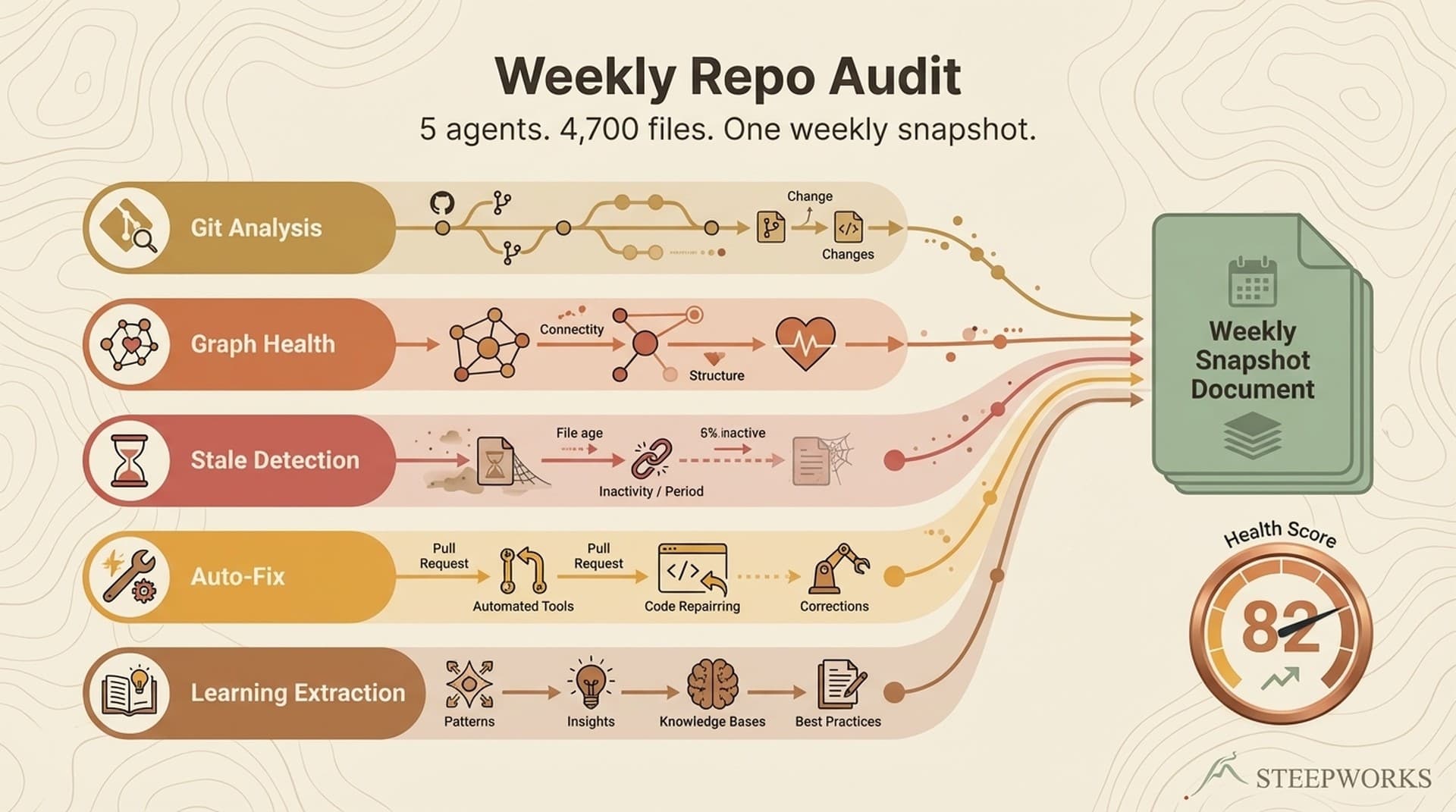
A weekly automated repository audit using a Claude Code agent catches an average of 30-50 issues per run across a 4,700-file knowledge repository -- stale references, orphaned files, broken cross-links, and missing metadata. Skipping a single week dropped the repository health score by 11 points, proving that large-file-count repos decay faster than most teams realize.
I skipped the audit one week. Just one. When I ran it the following Monday: 47 stale references, 12 orphaned files, a health score that had dropped 11 points. Nothing had broken visibly. No build failed. No user complained. But the repository I depend on for every AI-assisted workflow had quietly become less trustworthy in seven days.
In a 4,700-file repository, entropy does not announce itself. A missing metadata field here. A cross-reference pointing to a file that moved last Tuesday. A plan file left marked "active" three weeks after the work finished. None of these are emergencies alone. Together, after a few skipped weeks, they make every downstream agent slightly less reliable. And "slightly less reliable" compounds.
The same decay patterns appear at 200 files. If you have a Notion workspace with 300 pages, you have stale references and outdated content too. The scale changes the tooling, not the discipline.
So I built a weekly audit that uses 5 parallel AI agents to catch this drift before it compounds. It runs in under an hour, auto-fixes what it can, triages what it cannot, and produces a health score I track week over week. The part I did not expect: the most valuable output is not the fixes. It is the intelligence. The audit catalogs what I learned each week, tracks which workstreams are heating up or cooling down, detects patterns in how I use my own tools, and generates learning rules that feed a chief-of-staff agent providing daily briefings. This is AI code maintenance when you treat a repository as a living system, not a file cabinet.
Why Repositories Decay (and Why Code Review Doesn't Catch It)
Code review tools are excellent at what they do. Greptile, CodeRabbit, Qodo — they catch bugs in new code. They review the diff. But they only see what changed this week. They never examine the 4,699 files that did not change. They answer "Is this change good?" They never ask "Is what we already have still accurate?"
Repository decay is not about bugs. It is about entropy: pages going stale, references breaking as files move, experiments running past their expiration date, synthesis documents falling behind the files they summarize. The RepoAudit paper validates that LLM agents can reason about full-repository context, but production implementations that actually run weekly and act on findings remain rare.
Most teams treat their knowledge base as a write-mostly system. They add pages. They add documents. They rarely audit what already exists. The result is what I call knowledge debt: the gap between what you have documented and how findable, accurate, and current that documentation actually is.
A concrete example. During a routine audit, Agent B flagged a README referencing 12 documents. Three had moved to different folders during a reorganization two weeks earlier. Two had been deleted outright. Anyone following that README would hit dead ends for 5 out of 12 links. No code review would catch that. The files that changed did not trigger a review of the files that referenced them.
Graphite's work on AI code quality establishes the PR-level baseline well. The gap between "reviewing new code" and "maintaining a living repository" is where this audit operates.
The 5 Parallel Audit Agents
The audit runs 5 specialized agents, each with a focused job. I tried a single agent early on. It hallucinated more, took longer, and missed things. Separation of concerns applies to AI agents the same way it applies to microservices: give each agent a clear scope, specific tools, and a defined output contract.
Agent A: Git History Analyzer
Reads every commit from the past week, extracts which domains were most active and which were silent, and flags unusual patterns. Example: it surfaced a week where newsletter infrastructure had 30 file changes across scrapers and pipeline code but zero README updates. Heavy development without documentation updates usually means the docs are stale.
In Week 9, this agent processed 101 commits across 1,038 unique files, classifying them into 44 substantive commits, 33 stream captures, and 24 merge operations. The activity heatmap: .claude/skills/ took 40.6% of file touches, 04_projects/ got 29.2%, 10_automations/ took 11%. That distribution tells you where energy went, and where it did not.
Agent B: File System Scanner
The inventory agent. Checks every document for frontmatter compliance: does it have the metadata needed to be found, categorized, and trusted? Validates that files live in correct domain folders. Catches orphans — files that exist but are not referenced from any navigation hub.
Agent B found 81 files still tagged domain: shop that had been promoted to 04_projects/ months earlier. The files had moved. The metadata had not. Each fix takes 10 seconds, but at 81 files it is a batch operation — exactly what the remediation system handles.
Agent C: Knowledge Graph Health Checker
Calculates the 4-dimension health score covered in the next section. Validates every cross-reference: does each link point to a real file? Detects one-way links where document A references B, but B has no reference back. In a knowledge graph, one-way links are navigation dead ends.
Agent D: Active Work Detector
Catches organizational debt. Finds plan files still marked "active" for work completed weeks ago, surfaces stale experiments in prototype folders (no activity in 30+ days), and identifies cleanup candidates: temp files, draft versions, abandoned work.
In Week 9, it found 31 active plan files. After triage: 5 were duplicates, 1 was already complete, 4 moved to dormant. Active count dropped to 22 — still a lot, but each one now represents real work. When session recovery reads active plans at conversation start, it reads signal, not noise.
Agent E: Remediation Planner
Takes the issues surfaced by the first four agents and classifies them by fix complexity. Output: a ranked remediation plan of what to auto-fix, what needs approval, and what requires manual work.
Why parallelism matters: Sequential execution would take 30+ minutes of data collection alone. Parallel execution compresses Phase 1 to 8-12 minutes — the difference between a practical weekly discipline and an afternoon-long chore nobody does.
Design decision: In a team setting, each agent's output could route to the relevant content owner. The audit needs a weekly 15-minute review meeting where the approval batch gets triaged. Agents do the scanning. Humans make judgment calls.
The 4-Dimension Health Score
I needed a single number I could track week over week. Not because a single number captures everything, but because it makes the trend impossible to ignore.
Four dimensions, each weighted by how much pain it causes when it drifts:
| Dimension | Weight | The Question It Answers |
|---|---|---|
| Metadata completeness (Schema Compliance) | 30% | Does every document have the metadata it needs to be found and trusted? |
| Link integrity (Linking Health) | 25% | Do cross-references work, or are there dead links and one-way references? |
| Consistent categorization (Taxonomy Consistency) | 20% | Is your team using tags, domains, and categories the same way? |
| Findability (Discoverability) | 25% | Can every document be reached via navigation hubs, or are there orphans? |
The formula:
Overall = (Schema x 0.30) + (Linking x 0.25) + (Taxonomy x 0.20) + (Discoverability x 0.25)
A real Week 9 output:
Health Score: 82/100 (GOOD) — Delta: -1
Schema Compliance: 80/100 (weight 30%) delta: -2
Linking Health: 88/100 (weight 25%) delta: 0
Taxonomy Consistency: 86/100 (weight 20%) delta: +1
Discoverability: 74/100 (weight 25%) delta: -2
Auto-fixed: 8 items
User-approved: 4 items
Manual remaining: 6 items
The absolute score matters less than the delta. A 72 that has improved 5 points over 4 weeks means the system is getting healthier. An 88 declining 3 points per week means something is decaying, even though 88 sounds good.
Early weeks, the score sat in the mid-50s — not because the repository was chaotic, but because the measurement was new and honest about what was missing. Watching it climb to the 80s over several weeks proved the discipline works. Watching it slide from 84 to 80 over four weeks, because new files arrived without metadata and a skipped audit let the debt compound, proved the reverse.
CodeScene does this for code: quantifying technical debt as a trackable metric. This system applies the same principle to knowledge debt.
Auto-Fix vs. Manual-Fix Triage
The audit does not just report problems. It fixes what it can. The boundary between "fix automatically" and "ask a human" comes down to one principle: reversibility.
| Tier | Risk Level | Example | Action |
|---|---|---|---|
| AUTO-FIX | Low | Add missing last_updated field | Execute immediately, log to audit trail |
| APPROVAL-NEEDED | Medium | Move a file to a different domain folder | Present batch to user, await confirmation |
| MANUAL-ONLY | High | Update a synthesis document with new content | Add to action items for human work |
If git can undo it with a single revert, it is safe to auto-fix. If it requires judgment about where something belongs or what it should say, it needs human eyes.
In a typical week, the audit auto-fixes 10-20 items — mostly missing metadata fields and stale timestamps. Tedious corrections nobody wants to do manually but that erode quality if left unattended. 3-5 items go to the approval batch. 5-10 become manual action items. The auto-fixes alone save 30-40 minutes per week.
Week 9: auto-fixed 8 items (deleted Windows artifact files at root, moved 6 stray PNG screenshots to temp, deleted 5 duplicate active plan files, renamed a completed plan to its proper suffix). Four more went to approval (moving stale plans to dormant, deduplicating kanban task IDs, cleaning 273 cached Playwright screenshots, adding .wrangler/ to .gitignore). All approved in one pass — a 30-second review for 20 minutes of manual work.
The batch approval pattern matters. Medium-risk items are not presented one at a time. They are batched: "Here are 4 items that need your decision. Approve all, review individually, or skip all." This respects operator time while keeping the human in the loop for judgment calls.
Weekly Snapshots — The Memory Your Repository Never Had
Every audit produces a snapshot: a markdown document saved with a week-number filename. After a few months, these become a longitudinal memory of how the repository evolved.
Each snapshot contains:
- Executive summary with health score and delta
- 4-dimension breakdown with each score and its movement
- The week's accomplishments: commits, files changed, most active domains, merged PRs
- Fixes applied: auto-fixed and user-approved
- Outstanding work: active plans, stale items, kanban health
- Remaining manual items and recommendations
The real value is the trend index — a JSON file accumulating week-over-week data. The production trend:
W07: Health 84 | Compliance 97% | Orphans 1 | Stale 89 | Rules 0
W08: Health 83 | Compliance 97% | Orphans 0 | Stale 12 | Rules 4
W09: Health 82 | Compliance 60% | Orphans 0 | Stale 11 | Rules 4
W11: Health 80 | Compliance 41% | Orphans 610 | Stale 22 | Rules 8
Health score declined 4 points over four snapshots. Frontmatter compliance dropped from 97% to 41% — not because files lost their metadata, but because hundreds of new files arrived (demo datasets, course curriculum, scraper modules) that do not have frontmatter by design. Orphans jumped from 0 to 610 when a deeper link validation scan exposed systemic broken wikilinks from a plugin migration months earlier. Stale files spiked when a week was skipped.
The snapshot from six weeks ago records a pattern I would have forgotten: health dropped because a large batch of files arrived without metadata. Auto-fix caught most of it the following week, but the trend shows the dip and recovery. That pattern changed how I approach large file additions — I now add metadata as part of creation, not after.
The architecture that makes these snapshots meaningful is the same one described in I Migrated 4,700 Files Into a Knowledge Operating System. Without structured domains, consistent metadata, and navigation hubs, there would be nothing coherent to measure.
Learning Extraction — The Audit That Improves Itself
Most people will not expect this from a repository audit. The audit does not just measure health and fix problems. It learns. Phase 8 reads behavioral data from the repository and extracts patterns that become operational intelligence.
The system watches for 8 insight patterns:
- Skill chain gaps — Workflow sequences not being followed. Example: the content creation skill invoked 5 times in a week without the review skill ever following it. A quality gap hiding in behavior.
- Stale reference detection — High-activity directories with outdated synthesis documents. If a folder had 30 file changes but the README was last updated 3 months ago, the synthesis is lying.
- Workstream cooling — Areas with zero activity for 14+ days. When one of my 8 tracked workstreams goes silent for two weeks, the audit surfaces it. Sometimes cooling is intentional. Sometimes it is a dropped ball.
- Recurring fix patterns — The same auto-fix applied 3+ consecutive weeks signals a root cause. If the audit keeps cleaning up root-level PNGs every week, the real fix is a
.gitignorerule — which is exactly what happened. Learning rule lr-008 tracked screenshots declining from 89 to 36 to 6 once the pattern was added. - Health trend direction — 4-week moving average of improvement, decline, or flat.
- File co-access patterns — Files always accessed together but not cross-referenced, surfacing missing navigation links.
- Workflow bottleneck detection — Skills invoked repeatedly with failure patterns.
- PRD cycle time anomalies — Multi-phase plans taking longer than expected.
When the audit surfaces an insight, it presents it for review: Approve (becomes a learning rule for future sessions), Dismiss (noise), or Defer (revisit next week). Approved rules accumulate into a growing body of operational intelligence.
Learning rule lr-001 was generated when the audit detected that completed plan files were not being renamed from _active to _complete. The rule triggered a fix in two upstream skills: the execution skill now mandates renaming on completion, and the planning skill includes it in its checklist. The audit did not just find the problem — it encoded the fix into system memory so the problem stops recurring.
lr-005 detected health declining for three consecutive weeks (84 to 83 to 82) and identified the largest contributor: 81 domain mismatches from files promoted out of a staging folder but never updated with correct metadata. That became a prioritized batch update, expected impact +3 Schema Compliance points.
lr-007 surfaced that Markets2Mountains had 2 active PRDs but zero file activity for 3 consecutive weeks. Not a bug, but awareness that changes how the next session approaches that workstream.
The fixes keep the system clean. The learning extraction makes it smarter. And the learning rules feed a chief-of-staff agent that provides daily briefings, cross-referencing active goals against actual work to surface misalignment before it becomes a problem.
What Happens When You Skip a Week
The decay curve is not linear. One skipped week means roughly 15 unresolved issues. Two skipped weeks means roughly 40, because second-week decay compounds on unresolved first-week items. Three skipped weeks and the remediation plan fills an entire session.
The W10-to-W11 skip illustrates this. Health dropped from 82 to 80, but the numbers inside that 2-point drop were worse than they looked: Schema Compliance fell 2, Linking Health fell 3, Taxonomy Consistency fell 4, Discoverability fell 2. Every dimension declined simultaneously — something that had not happened in any prior week.
Specific decay patterns:
Stale metadata cascades. One file missing last_updated is a 10-second fix. Thirty files is a 45-minute batch operation. By Week 11, frontmatter compliance had dropped from 97% to 41%.
Reference rot. Files moved without updating cross-references create chains. Document A links to B's old location. Document C links to A. A reader following C hits a broken trail two hops deep. Agent C found 610 broken wikilinks in Week 11 from a plugin migration that should have been caught incrementally.
Active plan accumulation. When you have 29 active plans and only 7 represent real work, session recovery becomes slow and confused, loading stale context from plans that should have been marked dormant weeks ago.
The weekly audit is the difference between a repository that compounds value and one that slowly becomes unreliable. Skip it long enough and you stop trusting your own system — the moment AI-assisted workflows stop working, because the AI's context is only as good as the repository it reads.
This is the broader argument from Systems Over Tactics: Why Most AI Implementations Fail at Month 3. A one-time cleanup is satisfying. A recurring discipline is what compounds.
Building Your Own Weekly Audit
You do not need 5 agents or 4,700 files. You need a weekly check, a scoring system, and a record of the delta. My first version took about 2 days to configure. It has evolved over months, but the initial version caught 80% of what the current one catches.
Three elements, in order:
1. Pick your health dimensions (Week 1)
What matters in your repository? Code quality? Documentation coverage? Test coverage? Dependency freshness?
Define 3-4 dimensions. Weight them by what causes the most pain when it drifts. Schema Compliance gets 30% in my system because findability depends on metadata, and metadata decays first when files are created in a hurry.
You do not need a sophisticated scoring formula. A weekly checklist beats a weighted algorithm that runs never. Even a manual pass — "Are the READMEs current? Cross-references intact? Orphaned files? Anything marked active that should not be?" — is a step up from no audit at all.
2. Build the auto-fix / manual-fix boundary (Week 2)
List every recurring maintenance task. Classify each: can an AI agent do this safely (reversible, deterministic), or does it need human judgment?
Start conservative. Missing timestamps, stale PID files, screenshots in the wrong folder — mechanical. Moving a file to a different domain or rewriting a synthesis document — human territory.
Batch the approval items. One-at-a-time review is too slow. Present 5 items as a table: item, proposed action, risk level. Most weeks I approve all 3-5 in under a minute.
3. Start tracking the delta (Week 3)
Run your first audit. Record the score. Run it again next week.
After 4 weeks, you have a trend. After 8, a pattern. After 12, an operational habit that compounds. My trend index — a JSON file tracking 6 metrics per week — has become the most referenced artifact in my repository management system.
Once you have a few months of data, learning extraction becomes possible. You see which fixes recur (fix the root cause), which workstreams go silent (intentional?), and patterns in your own tool usage you would never spot from inside a single session. The audit becomes an intelligence system, not a cleanup script.
If your repository lives on GitHub, GitHub's agentic workflows provide infrastructure for scheduling automated tasks like this. For evaluating which AI agent platform can power your audit, Faros AI's survey of coding agents is a reasonable starting point — though my system runs on Claude Code, not a third-party platform.
The Audit as Intelligence System
A 4,700-file repository does not stay healthy by accident. It stays healthy because something checks on it every week — validating metadata, chasing broken references, surfacing stale work, auto-fixing what it can.
But calling this "maintenance" undersells it. The weekly audit turned my repository from a filing cabinet I searched into a living system I trust. The fixes keep the foundation solid. The health score makes decay visible. The snapshots create institutional memory. The learning extraction — cataloging lessons, tracking active workstreams, detecting workflow patterns, generating rules that feed a chief-of-staff agent — is where the compounding happens.
That trust is what makes every other AI-assisted workflow reliable. Agents read accurate context because the audit keeps it accurate. The chief-of-staff knows what is active because the audit tracks it. Session recovery loads relevant plans because the audit archives the stale ones.
AI code maintenance is not about catching bugs in pull requests. It is about treating your entire repository as a system that needs care — scheduled, measured, improved week over week. Not a janitor. An intelligence operation.
Frequently Asked Questions
How long does a weekly repo audit take to run?
The full audit runs in approximately 15-20 minutes on a 4,700-file repository. It checks file health, cross-references, metadata completeness, and structural integrity. The agent produces a scored report with prioritized fixes, most of which it can auto-remediate.
What kinds of issues does the audit catch?
The audit surfaces stale references pointing to moved or deleted files, orphaned documents with no inbound links, missing or malformed YAML frontmatter, broken internal cross-references, and files that have drifted from their domain's quality standards. These are invisible failures -- nothing breaks visibly until someone depends on the bad data.
Can this approach work on codebases, not just knowledge repos?
Yes. The audit pattern applies to any repository with cross-file dependencies: documentation sites, monorepos with shared configs, content management systems, and wiki-style knowledge bases. The specific checks change, but the entropy-detection architecture is the same.
What happens if you skip the audit for multiple weeks?
Entropy compounds nonlinearly. One skipped week produced 47 issues. In testing, two skipped weeks produced 90+ issues with cascading dependencies -- fixing one broken reference revealed three more downstream. The cost of remediation grows faster than the calendar gap.
This pattern is part of the Knowledge OS architecture — the three-layer system that makes AI compound over time.