title: "Compound Knowledge Architecture: Why AI Gets Better" slug: compound-knowledge-architecture seo_keyword: "AI knowledge compound" meta_description: "AI knowledge compound: why some AI systems improve every month while tools plateau. The compound architecture separating the 5% from everyone else." og_description: "Your AI tool forgot everything from yesterday. Here's the architecture that makes AI knowledge compound instead of reset -- and why the gap widens every month." cluster: ai-strategy author: Victor status: published published_date: 2026-03-26 read_time_minutes: 12 description: "Compound Knowledge Architecture: Why AI Gets Better" domain: steepworks type: article updated: 2026-03-26
You spent 45 minutes teaching an AI tool your company's positioning. You walked it through your ICP, your tone of voice, the three things you never want to say in outbound. The output was good. Maybe great. You closed the tab.
Next morning, you open a new session. The tool has no idea who you are. No memory of the positioning. No memory of the ICP. No memory of the three forbidden phrases. You start over. Again.
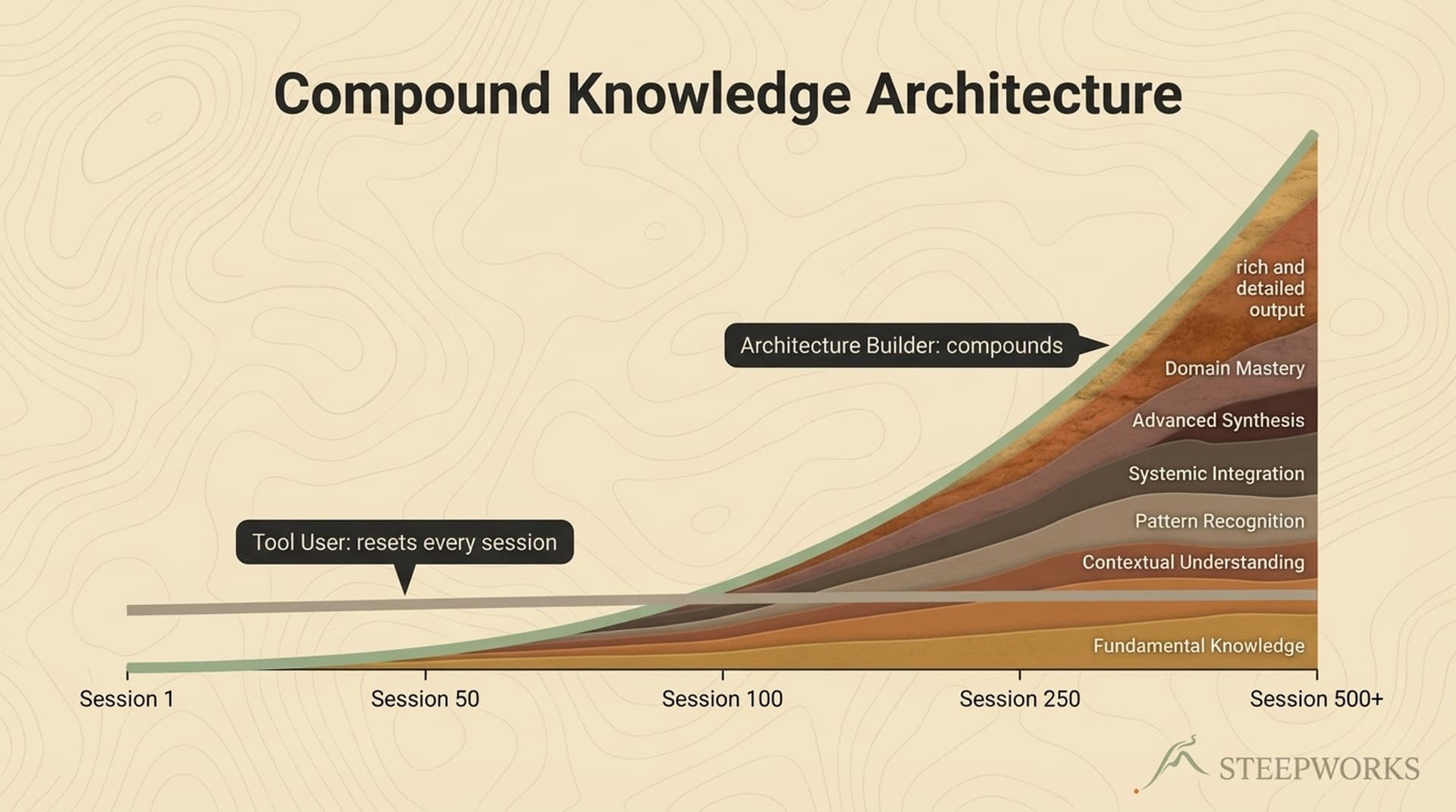
This isn't a bug you can report. It's architecture. And it's the reason your AI knowledge doesn't compound -- every session resets to zero, and session 100 delivers the same baseline quality as session 1.
I've spent the past ten months building a system where AI gets measurably better over time. Not because the model improved, but because the system around it accumulates knowledge. The gap between "tool users" and "system builders" is already wide, and it widens every month. This article explains why.
If you've read why systems beat tactics, this is the economic engine underneath that argument. If you've read the four-layer architecture breakdown, this is the growth dynamics that make that architecture worth building. This article is about compounding -- why some AI setups produce increasing returns and others flatline.
The Reset Problem -- Why Your AI Starts From Zero Every Morning
Here's what most people don't realize about AI tools: your chat history isn't learning. It's a transcript.
The model itself suffers from what researchers call "catastrophic forgetting" -- training on new information actively degrades existing knowledge. This is a well-documented constraint in continual learning research, not a product limitation that next quarter's update will fix. The model cannot retain your corrections without losing something else. Custom instructions help, but the model doesn't get smarter from your feedback. It starts each session with the same weights it had when you first signed up.
The result is linear value. You pay the same context-loading cost every time you use the tool. You re-explain your company. You re-state your preferences. You re-correct the same mistakes. The effort per session stays flat because the tool brings nothing forward.
Now imagine the same AI, but it already knows your positioning because it reads a document you wrote once and update monthly. It knows your ICP because it references a profile that improves every quarter based on which prospects actually converted. It knows your tone because it's seen 40 examples of content you approved. Session 100 is dramatically better than session 1 -- not because the model improved, but because the system accumulated knowledge.
That's the difference between a tool and a system. And it's why some teams see AI get better every month while others hit a plateau at week three.
The data backs this up at scale. BCG's September 2025 study of 1,250+ firms found that only 5% achieve AI value at scale. 60% report no material value at all. The 5% didn't find better tools. They built systems where AI knowledge compounds.
Tools vs. Systems -- The Compounding Gap
A tool is stateless. It processes an input and produces an output. It brings nothing forward from one use to the next. ChatGPT, Jasper, a standalone Claude conversation -- these are tools. Powerful tools, but tools.
A system is stateful. It accumulates context, captures what worked, and feeds that knowledge into the next cycle. The output of one interaction becomes the input for the next. Over time, the system's baseline quality ratchets upward without additional effort.
Here's a diagnostic you can run on your own AI usage right now:
| Dimension | Tool (Linear) | System (Compound) |
|---|---|---|
| Memory | None -- session dies when you close the tab | Persistent -- context docs, learning rules, history |
| Session 1 vs. Session 100 | Same quality | Dramatically better |
| Knowledge lifecycle | Created, used, discarded | Created, accumulated, refined, compounded |
| User effort over time | Constant (same setup cost every time) | Decreasing (system handles more context automatically) |
| Value curve | Linear -- each use delivers equal value | Compound -- each use makes the next one more valuable |
| Failure mode | Abandoned when novelty fades | Refined when friction surfaces |
If everything in your column lands on the left, you're getting linear returns from AI. That's not a criticism -- it's where most people start. But it explains why the tool stopped feeling impressive after a few weeks.
"But I already use ChatGPT with custom instructions / Notion AI / Glean..."
Fair point. Custom instructions move toward compounding, but they're manually maintained, not system-maintained. Notion AI can search your notes, but it doesn't learn which notes matter most for which tasks. Glean indexes your docs, but it doesn't capture what worked and feed it forward. The difference is between passive retrieval (tool finds what you stored) and active accumulation (system captures, evaluates, and compounds what it learns).
The failure data is consistent. RAND's analysis found 80%+ of AI projects fail, with a primary root cause being "technology-first thinking" -- choosing the tool before understanding the workflow. Tools are the technology-first approach. Systems are the workflow-first approach.
And the compounding math is stark. Cypris research calculated that an organization compounding knowledge at 15% annually has 4x the knowledge capability after 10 years versus a fragmented competitor. The same math applies at the team level -- small architectural investments early produce outsized returns later.
The Three Layers That Make AI Knowledge Compound
This is where "compound" stops being a metaphor and becomes something you can build. Three architectural layers, each solving a specific problem you've probably already felt.
Layer 1 -- Persistent Context (The Foundation)
The problem it solves: "I have to re-explain my company to the AI every single time."
Persistent context means the AI reads your positioning, ICP, tone guidelines, and competitive landscape before every interaction -- automatically. Not because someone remembered to paste it in, but because the system loads it by default.
What this looks like in practice: a single context document that every AI session reads first. It contains your company's positioning, your ICP definitions, your communication style. When you update it once, every future interaction reflects the update. One write, infinite reads.
I maintain a shared context document that includes our positioning, ICP profiles with their specific pains, a positioning comparison table (us vs. competitors), messaging pillars, and voice standards. Every AI skill -- from content production to prospect research to meeting prep -- reads that document before executing. When I refine the ICP based on which prospects actually converted last quarter, every downstream skill produces better-targeted output. That's compounding: one improvement propagates across dozens of workflows.
Time cost: About 2-4 hours to create the initial context document. Maybe 30 minutes per month to maintain. It pays back within the first week.
Layer 2 -- Learning Rules (The Memory)
The problem it solves: "The AI keeps making the same mistakes, and I keep correcting the same things."
Learning rules capture operational knowledge: what works, what broke, what to avoid. They're not prompt templates -- they're accumulated wisdom from production use.
Every correction you make to an AI output is a learning opportunity. Without learning rules, that correction exists in one conversation and vanishes. With learning rules, that correction encodes into a persistent rule that prevents the same mistake across every future interaction.
A concrete example. After discovering that certain newsletter opening styles consistently underperformed, I encoded a learning rule: "Newsletter openings must open with the idea itself (a claim), not a greeting or meta-commentary." That rule now applies to every newsletter draft the system produces. One correction, permanent improvement.
I have 21 active learning rules accumulated over months of production use -- each one representing a mistake that will never recur. [Measured -- tracked in a production JSON file with IDs, creation dates, severity levels, and resolution notes.] They cover everything from content voice to infrastructure patterns to data integrity. Each rule has a severity level and an active flag. Some resolved upstream problems in the skills themselves; others serve as ongoing guardrails.
The compound effect: each learning rule makes the system slightly better. After 20+ rules, the system's baseline quality is meaningfully higher than day one -- without the model itself changing at all.
Time cost: About 5 minutes per rule when you notice a pattern. The rules accumulate naturally through daily work. You don't sit down to "write learning rules" -- you notice something broke twice, and you encode the fix.
Layer 3 -- Skill Chains (The Multiplier)
The problem it solves: "Each AI tool works fine alone, but none of them talk to each other." (See also: ai gtm)
Skill chains connect multiple AI capabilities in sequence, where each step's output feeds the next step's input. Research feeds analysis. Analysis feeds content. Content feeds distribution. Distribution feeds measurement. Measurement refines the next research cycle. (implementation consulting)
When Layer 1 (persistent context) and Layer 2 (learning rules) are available to every skill in the chain, improvements to context or rules propagate through every connected skill. Update your ICP document, and your prospect research, outreach, and content skills all improve simultaneously. (See also: operator identity)
Our content production chain runs through five skills in sequence: research, outline, buyer-critique, revision, and quality gate. Each skill reads the same persistent context and learning rules. When I add a learning rule to the content workflow (e.g., "never use corporate jargon like 'leverage' or 'synergy'"), it applies to every future article across every topic. The chain compounds because improvements to shared resources propagate across all connected skills.
The mechanism: skills don't copy context -- they reference it. One context file, loaded conditionally by every skill that needs it. Update the file once, and every skill in every chain sees the change on its next run. That's the difference between an integration and an architecture.
Every.to calls this "compound engineering" -- where roughly half of engineering effort goes to building features and the other half to improving the system itself, so each feature makes the next feature easier to build. Same principle, different domain. (pricing and tiers)
For the complete four-layer architecture breakdown, including the orchestration layer I haven't covered here, see AI Knowledge Architecture.
The Compounding Curve -- What Month 1 vs. Month 6 Actually Looks Like
The hardest part of compounding is that the early returns don't look special. That's by design.
Month 1: The system performs roughly the same as a standalone tool. You've invested time building context documents and configuring skills, but the output quality is comparable. This is where most people evaluate -- and where the investment looks like overhead.
Month 2-3: The system starts pulling ahead. Context documents have been refined once or twice based on real outcomes. A handful of learning rules have accumulated. Skills reference better context. The gap between "start from scratch" and "start from context" widens visibly.
Month 4-6: The system is materially better than a tool approach. 20+ learning rules prevent recurring mistakes. Context documents include examples of what actually worked, not just initial positioning. Skill chains run end-to-end with minimal manual intervention. New skills build faster because they inherit context and rules from existing ones.
Here are the actual numbers from my production system, labeled honestly:
- Context documents: Started at 2 pages of positioning. After 6 months, includes 100+ examples of approved outputs organized by use case. [Observed in production]
- Learning rules: 0 on day one. 21 active rules after 10 months. Each one represents a mistake that no longer recurs. [Measured -- tracked in a production system, verifiable count]
- Skill count: Started with 3 basic skills. Now running 45+ skills across 8 workstreams, all sharing the same persistent context. [Measured -- skills are files in the repository, countable]
- Skill invocations: 1,400+ logged runs across those skills, tracked in a usage ledger with timestamps and workstream tags. [Measured -- append-only log file]
- Time per task: Meeting prep that took 30 minutes in month 1 takes roughly 10 minutes in month 6, because the system pre-loads account history, recent interactions, and relevant context automatically. [Estimated from workflow observation]
The distinction that matters: tools are a subscription. You pay the same cost each month and own nothing. Systems are an asset. The same monthly effort accumulates into something worth more over time. By month 6, you own accumulated institutional intelligence -- context documents, learning rules, skill chains -- that a tool user can never match no matter how many hours they spend in ChatGPT.
For the full architectural story of how this system was built from zero to 4,700+ files, see Building a 4,700-File Knowledge OS.
Why Tools Cannot Compound (The Tool-Hopping Trap)
There's an anti-pattern I see constantly, and it needs a name: tool-hopping.
Tool-hopping is switching AI tools every quarter hoping the next one will produce compound returns. New model drops? Switch. New wrapper app? Switch. Colleague recommends something? Switch. It never works because the problem isn't the tool. It's the architecture. A better model inside the same stateless wrapper produces the same linear value.
"But ChatGPT has memory now." Yes -- and it's a step in the right direction. But tool-level memory is shallow: it stores facts you explicitly told it. It doesn't capture patterns from what worked versus what didn't. It doesn't propagate learning across multiple workflows. It doesn't get richer without your active effort. It's a notebook, not a learning system.
Three structural barriers prevent tools from compounding, and they're architectural, not a product gap that the next update will close:
-
No persistent context architecture. Tools don't read your company's positioning before every interaction. You bring the context manually, or the tool operates without it. When you forget to paste it in on a busy Tuesday, the output quality drops to baseline.
-
No learning capture. When you correct a tool's output, that correction lives and dies in one conversation. The tool makes the same mistake next time because it has no mechanism to encode "don't do that again" across sessions. Your tenth correction of the same error is exactly as effective as your first -- which is to say, not at all.
-
No cross-workflow propagation. Even if a tool improves in one workflow, that improvement doesn't transfer to other workflows. Your email tool doesn't learn from your research tool. Your content tool doesn't learn from your outreach tool. Each workflow is an island.
Berkeley BAIR's landmark 2024 paper argued that state-of-the-art AI results increasingly come from compound systems, not monolithic models. The lesson applies to business AI too: the compound system -- where models, retrievers, memory, and tools interact -- outperforms any single model used in isolation.
The uncomfortable implication: if you're evaluating AI tools individually, you're structurally producing linear returns. The evaluation framework itself prevents compounding. The question isn't "which tool is best?" It's "which architecture enables my AI knowledge to compound?"
Building Your First Compound Layer (Start Here)
You don't need to rebuild your infrastructure. You don't need a new platform. You need one architectural change: give your AI persistent context.
The one-document start. Create a single context document -- 1-2 pages -- that contains:
- Your company's positioning in 2-3 sentences
- Your primary ICP with their top 3 pains
- Your communication tone with 3-5 examples of approved output
- A short list of things to never do ("never use the word 'leverage,'" "never claim we're the #1 solution")
Feed this document to every AI interaction. In Claude Code, this is a CLAUDE.md file. In other tools, it might be custom instructions, a system prompt, or a shared context file. The format matters less than the persistence.
The immediate effect: your AI outputs jump in quality because they start from your context, not from zero. But the compound effect kicks in over weeks: as you notice patterns (what works, what doesn't), you add to the document. Each addition improves every future interaction across every workflow that reads it.
Here's the timeline:
- Week 1: Create the context document. Feed it to your primary AI workflow. Notice the quality difference immediately.
- Week 2-4: Every time you correct an AI output, ask yourself: "Is this a one-time fix, or a pattern?" If it's a pattern, add it to the context document. This is your first learning rule.
- Month 2-3: You now have 5-10 learning rules and a richer context document. Your AI's baseline quality has shifted upward. The compound curve has started.
For reference, IDC data shows enterprise organizations seeing an average of 3.5x ROI on AI knowledge system investments, with mature adopters reporting up to 10x. These numbers come from large-scale deployments -- at small-team scale, the absolute figures differ, but the compound curve holds. Early architectural investment disproportionately outperforms late tool adoption regardless of team size.
"What if my team won't adopt this?" Start with your own workflow. When your results visibly improve -- when your emails are sharper, your research is faster, your content needs fewer revisions -- adoption follows demonstration. On small teams, one person's visible results are the most persuasive change management there is.
This article is the economic engine behind the systems-over-tactics argument. Systems compound. Tactics don't. The architecture creates the compounding.
The Architecture Decision That Determines Your AI ROI
The AI tools will keep improving. Every quarter brings better models, better benchmarks, better capabilities. But here's what won't change: a better model used as a stateless tool still produces linear value. A mediocre model embedded in a compound knowledge system will outperform it within months -- because the system accumulates what the model cannot.
The 5% of companies in BCG's study that generate AI value at scale didn't find a secret tool. They made an architecture decision: they built systems where knowledge persists, learning accumulates, and each cycle makes the next one better. The other 95% bought tools.
The compounding math is relentless. Cypris calculates that an organization compounding at 15% annually has 4x the knowledge capability after 10 years. Competitors who start building compound knowledge architecture now will be unreachable by the time you notice the gap. This isn't a feature comparison you can catch up on by switching vendors. It's accumulated institutional intelligence that compounds with time.
The decision in front of you isn't "which AI tool should I buy?" It's "am I building an architecture where my AI knowledge compounds, or am I renting tool access that resets to zero every session?"
Start with one context document. Add learning rules as you go. Connect your first skill chain. The compound curve does the rest. Not magic. Architecture.